







BBC:人类首张蛋白质组草图绘制完成
一个德国的团队和一个美国印度联合团队将他们的蛋白组图谱发表在了《自然》杂志上,他们的结果在公共网站上也可搜索到。
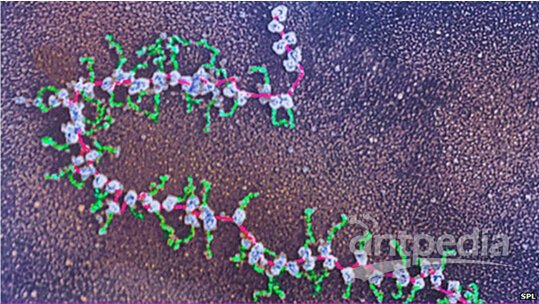
Figure 1蛋白(绿色)由中间的RNA(粉色)分子翻译所得,RNA则由我们的基因复制所得
他们首次试图建立起关乎每一个人的蛋白质数据库。这些结果基于我们对基因组的了解---我们知道何种基因在何种组织中生产蛋白质。
研究共报道了17,000至18,000种蛋白质。其中一些来自曾经认为是非编码的DNA片段。
在我们的每一个细胞中所包裹的超长DNA上,我们的基因只是其中的一部分,它包含用于生产蛋白质的指令和代码。
“虽然我们对基因组已经有了不错的了解,却还不知道这将近20,000个能用来编码的蛋白质基因中有多少能真正用以生产蛋白质。” 带领德国团队的慕尼黑工业大学Bernhard Kuester教授说。
意想不到的结果
为了找出答案,研究人员从人体组织的许多不同的样品以及一些细胞系中提取所有蛋白质。接着将这些纯化后的混合物中的蛋白切碎成小片段,利用质谱技术揭示组成每一个小片段的氨基酸序列。
凭借强大的计算资源及足够的耐心,我们可以将这一批蛋白质片段与人类基因组进行比较,从而制作图谱,以显示哪些组织中的哪些基因被“表达”而产生蛋白。
Figure 2为了将组成人体的所有蛋白进行编排,研究人员使用了一系列的样品,包括成体组织,胎儿组织和许多细胞系
“如果你喜欢这种说法,这是(人类蛋白质组的)第一份清单,” Kuester教授告诉BBC新闻记者,“就像十几年前人类基因组的初稿那样。”
并且正如人类基因组计划的结果一样,这些数据中包含了一些惊喜。
两组团队均发现了数百种意想不到的蛋白质,它们是由古基因(称为“伪基因”)片段或者那些根本不认为是基因的DNA片段产生。
除了这些蛋白质的新成员之外,还有一些明显的“缺席者”。“我们有充分的理由相信,数百个已知的,且已经被解析的基因,它们也许是多余的。” Kuester教授说。
美印团队,由美国巴尔的摩约翰霍普金斯大学教授AkhileshPandey领导。他们的研究找到了一些证据,证明从基因组中我们只能预测全部蛋白质的84%。
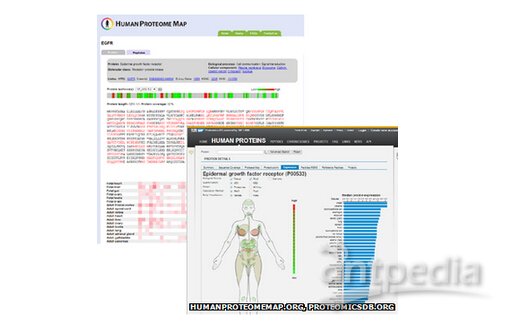
超越遗传学
Pandey教授告诉BBC,研究蛋白质本身与研究编码它们的基因同样重要。
说到研究特定基因的研究者如何利用这个新数据库,他举了一个例子:“他们可以观察蛋白质的表达并且知道这个蛋白质的作用。比如说,如果一个蛋白质在胎儿肠道而非成人肠道中表达,那么他们或许应该考虑这个蛋白质可能参与了发育过程。”
组织依次分解的方法也可以帮助科学家们弄清药物的作用及副作用。通过比较不同癌细胞系的蛋白质组,Kuester教授和他的团队已经确定了一些蛋白质簇,这些蛋白质可以增强或减弱对癌症药物的敏感性。
Kevin Mills博士曾使用蛋白质组学研究了UCL儿童健康研究所的罕见病例,他认为在蛋白水平上观察“超基因组学”并观察它们如何变化非常重要。
“遗传学不能告诉我们一切,” Mills博士说道,他并没有参与上述两项研究。“这的确是非常重要的。我们并不是静止的——我们是不断变化的,我们的蛋白质组也在持续地变化着。”
他们在会议上看到过彼此的工作,但Pandey教授和Kuester教授告诉BBC新闻,他们并不知道会同时发表结果。上周,他们发现他们的工作将同时在《自然》的封面上闪亮登场时,彼此通了一个电话。
“我们从未把这当成是争夺冠军的竞赛,” Kuester教授说,“我的理解是,当时机成熟的时候,自然会有某个人去做。或许是某两个人!”
Pandey教授将如今的联合发表结果与人类基因组的初稿做了一个比较,那是2001年2月由两个不同的团队公布的。

Figure 3 Pandey教授(中)和他的团队花了两年的时间生成并分析了这些数据
“虽然两个团队得到了类似的基因数目,但他们的基因列表是很不同的,”他说。“我们的结果在一致性上要好很多,不过把两份数据放在一起绝对是有益的。
-
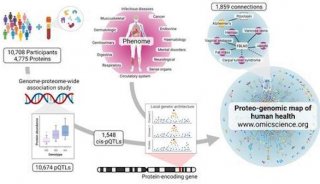
科技前沿
-
科技前沿
-
会议会展

-
项目成果
-
焦点事件

-
技术原理











