权威学者Nature子刊公布数据分析新方法
生物数据大爆炸带来了无限可能,我们能从浩瀚的数据库中寻找到帮助临床医师们做出更正确判断,进行个体化医疗的许多信息,但是从设想走到现实还有很长的路要做。
11月7日的Nature Genetics杂志公布了一项最新数据分析工具成果,来自哥伦比亚大学和普林斯顿大学的研究人员利用一种新的机器学习算法扫描大量的遗传数据集,从中推断个人祖先的遗传组成,识别疾病相关的遗传突变。
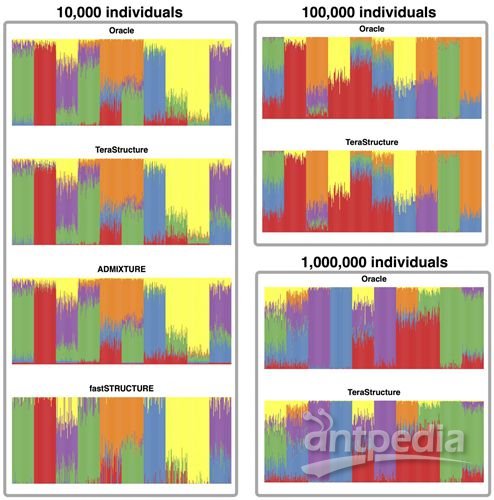
这种新技术就是 TeraStructure ,在针对一万人的模拟数据集中, TeraStructure 评估人群结构的精确性要比目前的运算方法更高,速度要快一倍。单独使用 TeraStructure能分析上百万的个体人群,这个数量级远超目前的软件方法,而且这一算法还能评估世界级别人口数量的特征。
“很高兴能将我们的最新数据分析工具用于遗传学实际问题,”文章作者,哥伦比亚大学统计学教授David Blei说。Blei是哥伦比亚大学统计学与计算科学教授,主题模型领域权威人物,他与吴恩达博士(百度首席科学家,全面负责百度研究院)师出同门。
随着基因测序成本的降低,目前全球大约已经进行了百万个个体的基因组测序,到2025年这一数字将会增长至20亿。然而要将这些数据应用到临床,识别基因组中的致病突变,研究人员还需知道这些数据代表了什么,其中之一就是了解个体祖先的遗传变异。
TeraStructure 基于2000年首次公布在Genetics 杂志上的一种 STRUCTURE 算法,这种算法会在整个数据集中循环,一个基因组再一个基因组,筛选上百万个突变。
而TeraStructure会更新模型,它能在一个位置上检验一个遗传突变,然后将其与整个数据集中同一位置的所有突变进行比对,得到一个群体结构的工作预测,“这无需在每个点上每次都更新模型。”
在STRUCTURE 基础上,Blei等人提出了一些新想法,他们分析了两个真实世界数据集:来自斯坦福大学Human Genome Diversity Project 的940个个体基因组,以及千人基因组项目中的1,718个基因组集合。从中他们发现TeraStructure 可以媲美于最近的ADMIXTURE 和 fastSTRUCTURE 运算方法。
但当他们在万人基因组数据集中运行TeraStructure 之后,发现这在预测人群结构方面要更加精确,而且速度要快2-3倍。同时研究人员还发现 TeraStructure 也能单独分析多达十万和百万的基因组。
这一成果一出来,不少科学家们纷纷表示这项成果令人激动,“我认为这将有助于未来解决具有挑战性的多种问题,”来自芝加哥大学的遗传学研究员Matthew Stephens说。
-
焦点事件