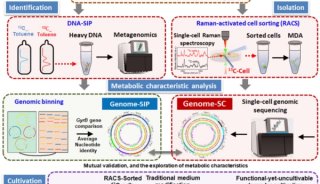
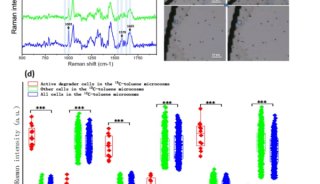
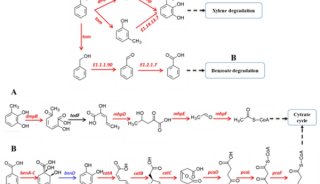
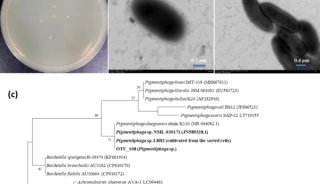
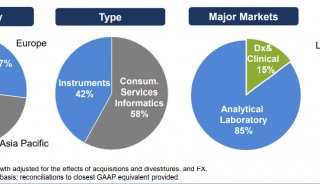
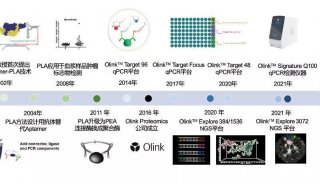
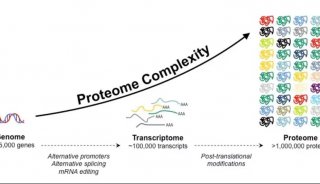
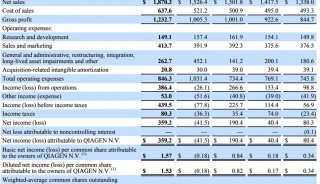
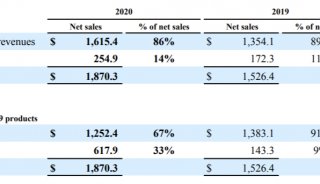
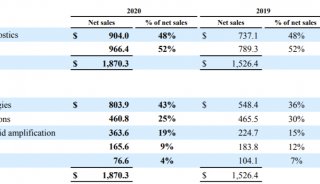
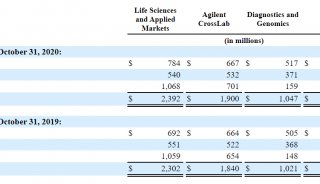
北京生科院提出编码基因重建的新方法
2016年11月,国际学术期刊《基因组生物学》(Genome Biology)在线发表了中国科学院北京生命科学研究院计算基因组学实验室研究员赵方庆团队题为A novel codon-based de Bruijn graph algorithm for gene construction from unassembled transcriptomes 的最新研究成果。该研究提出一种基于密码子de Bruijn图的新算法,使用非拼接策略直接对转录组测序数据进行编码基因识别和重建,解决了编码基因识别效率低且不完整的难题,该方法在非模式生物的进化基因组研究领域具有很大的应用前景。
近年来,高性能计算技术和高通量测序技术的快速发展促进了大量基因组测序计划的实施完成,从而获得了海量的生物组学数据。面对转录组数据,科学家们的首要任务是获得它们的编码基因信息。传统的基因识别工具主要依赖于RNA-seq组装软件得到的转录本进行基因鉴定。这些工具的缺点之一是组装软件对测序错误高度敏感并且不能有效处理重复序列区域,因此导致在此基础上进行基因识别会产生大量高度冗余和片段化的基因序列。此外,这些工具需要过度依赖同源基因数据库或参考基因组,不能有效地应用于非模式物种的转录组数据的基因识别。因此,一种基于转录组数据重建编码基因的新算法亟待开发。
北京生科院赵方庆团队针对转录组数据分析中的编码基因识别问题,开发了一种基于密码子de Bruijn图的新算法inGAP-CDG。该方法不依赖于参考基因组,直接从未拼接的转录组测序数据中进行基因识别。通过使用模拟数据集和公共数据库的真实转录组测序数据,他们对预测基因的长度、灵敏度、冗余度、错误率和杂合度进行了系统性的评估。与其它方法相比,inGAP-CDG构建出的编码基因序列具有长度更长、冗余度更低和特异度更高的优势。该研究为基因识别提供了新的思路和方法,进而对此后的系统发育和功能基因组学研究具有重要的应用价值。inGAP-CDG已公开发布在免费的开源网站SourceForge上(https://sourceforge.net/projects/ingap-cdg/),以方便相关研究者下载使用。
该工作由赵方庆课题组的博士研究生彭公信和冀培丰共同完成,并得到国家自然科学基金委和科技部重点研发计划的经费支持。

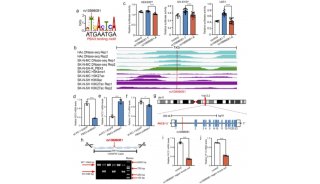
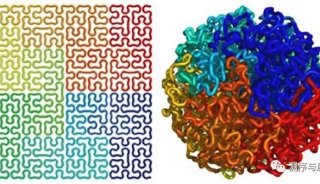
基于转录组数据(左)和基因组数据(右)的de Bruijn图
-
企业风采

-
焦点事件

-
会议会展

-
财报

-
科技前沿

-
项目成果
-
焦点事件

-
焦点事件

-
财报

-
会议会展

-
产品技术

-
企业风采

-
产品技术

-
企业风采

-
企业风采

-
企业风采

-
企业风采

-
企业风采

-
会议会展

-
企业风采

-
财报

-
焦点事件

-
财报

-
财报

-
并购

-
焦点事件

-
焦点事件
-
企业风采

-
焦点事件
-
企业风采

-
并购
-
焦点事件
-
企业风采

-
焦点事件

-
财报

-
焦点事件

-
焦点事件
-
焦点事件
-
企业风采

-
产品技术

-
企业风采

-
投融资
-
企业风采

-
焦点事件

-
财报

-
焦点事件

-
科技前沿

-
企业风采

-
项目成果
-
企业风采

-
财报

-
企业风采

-
产品技术

-
焦点事件

-
科技前沿

-
科技前沿

-
财报

-
财报

-
并购

-
科技前沿

-
科技前沿

-
焦点事件
-
科技前沿

-
招标采购

-
财报

-
会议会展

-
企业风采

-
科技前沿
-
投融资

-
企业风采

-
科技前沿

-
会议会展

-
企业风采

-
并购

-
焦点事件

-
企业风采

-
企业风采

-
科技前沿

-
科技前沿

-
科技前沿
-
科技前沿
-
项目成果
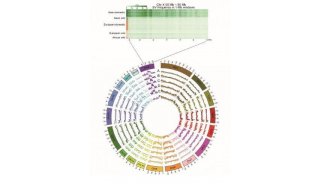
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
项目成果
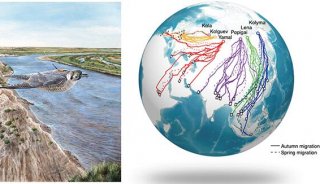
-
企业风采

-
产品技术

-
项目成果

-
企业风采

-
企业风采

-
企业风采

-
企业风采

-
焦点事件

-
企业风采

-
企业风采

-
企业风采

-
企业风采

-
科技前沿
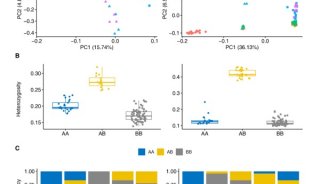
-
企业风采

-
财报

-
焦点事件

-
项目成果

-
项目成果

-
项目成果

-
产品技术

-
项目成果

-
企业风采

-
焦点事件

-
焦点事件

-
财报

-
项目成果

-
财报

-
精英视角

-
并购

-
财报

-
项目成果
-
焦点事件

-
综述
-
项目成果
-
焦点事件

-
焦点事件

-
焦点事件

-
财报

-
焦点事件

-
技术原理

-
焦点事件

-
财报

-
企业风采

-
焦点事件

-
产品技术

-
综述

-
项目成果
-
项目成果

-
项目成果

-
焦点事件

-
焦点事件

-
项目成果
-
产品技术

-
焦点事件

-
会议会展

-
综述
-
科技前沿
-
科技前沿
-
项目成果
-
会议会展

-
企业风采

-
企业风采

-
焦点事件

-
并购

-
焦点事件

-
企业风采

-
企业风采

-
科技前沿
-
财报

-
焦点事件

-
实验室动态

-
财报

-
财报

-
项目成果

-
并购

-
产品技术

-
人物动向

-
企业风采

-
并购

-
财报

-
企业风采

-
焦点事件

-
会议会展

-
产品技术