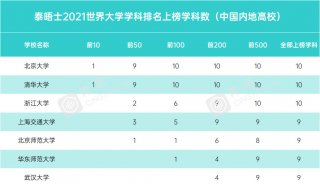
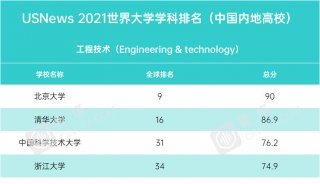
《自然》杂志解密百年来最高引用率研究成果
高温超导体的发现、DNA双螺旋结构的确定、宇宙膨胀加速的最早观察结果,所有这些突破都获得了诺贝尔奖和国际认可。但这些论文从未宣称自己跻身有史以来引用率最高的百篇论文之列。
引用是作者承认早期研究的方法、理念和发现的标准手段,并且通常被当作衡量一篇论文重要性的粗略标准。50年前,Eugene Garfield发行了科学文献索引(SCI),这是首个追踪科学文献引用的系统性努力。在周年纪念到来之际,《自然》杂志携手汤森路透(目前是SCI的拥有者),罗列了有史以来引用率最高的100篇论文。该研究涵盖了汤森路透全部数据库——SCI的在线版本,也涵盖了社会科学、艺术与人文、会议记录和一些书籍。论文的发表时间从1900年至今。
该研究得出了一些出乎意料的结论:至少得出要位居前100必须有12119次引用的惊人结果,而许多世界上最知名的论文都未能达到这一标准。前100名中,一些确实是经典成就,例如首次发现碳纳米管(第36位)。但大多数描述实验方法和软件的论文成为其领域的重要资料。
例如,历史上被引用次数最多的是一篇1951年的论文,描述了一个确定溶液中蛋白质数量的实验。到目前为止,它共被引用了30.5万次。这个数字也让该论文的第一作者、美国生物化学家Oliver Lowry感到不解。他在1977年写道:“我确实认为它并不是一篇极好的文章,但我依然从这样的反响度上得到了极大快乐。”
如果整个汤森路透的数据库是一座乞力马扎罗山,那么这100篇引用率最高的论文只相当于山顶的1厘米。只有14499篇论文的引用率超过1000——这也只占1.5米的高度。同时,山麓上的论文可能只被引用过一次。
荷兰科学和技术研究中心主任Paul Wouters表示,许多研究方法论文“成为一个标准的参考,以便让其他科学家明白自己在做的工作是什么”。另一个科学惯例是真实的基础研究(例如爱因斯坦的狭义相对论)获得的引用比它们应得的更少:它们如此重要,能很快地进入教科书,或成为论文正文的一部分——这些理论如此著名已经不需要标注引用。
引用计数也会受到其他混合因子的影响。例如,发表时间早的论文有更多时间积累引用量、生物学家的引用量高于物理学家、并非所有领域的出版物数量相同等。
另外,谷歌学术也曾为《自然》杂志编辑了100篇顶级论文。在这份名单里,经济学论文成绩最为突出。谷歌学术还突出了书籍的排名,而汤森路透并没有对此进行分析。但在科学论文中,两份名单有一些重合。
无论遭到多少质疑,这种老式的名人堂依然有价值。它能作为自然科学知识的提醒。研究人员正在依赖着相当多的被埋没的关于实验方法、数据库和软件的论文,这是令人激动的进步。
生物技术
数十年来,前百位论文名单始终被蛋白质生物化学界所主宰。上述1951年论文一马当先牢牢占据首位。尽管许多生物化学家表示,该论文与Bradford法相抵触,已经有些过时,后者位列第三。位居第二的是用于不同蛋白质分析的Laemmli缓冲液。这些技术的高排名归功于细胞和分子生物学的大量引用。
前100位论文中,至少有2种生物学技术获得诺贝尔奖。排名第四的论文(作者Frederick Sanger)描述了DNA测序技术;第63位的论文(作者Kary Mullis)讲述了聚合酶链反应,其作者均因此获得诺贝尔奖。
其他方法虽然受到的关注度较低,但仍获得不小的回报。上世纪80年代,意大利癌症遗传学家Nicoletta Sacchi与波兰分子生物学家Piotr Chomczynski在美国发表了从生物样本中提取RNA的一个快速、廉价方式。目前,这篇论文排名第五。Sacchi表示自己并未从这项技术中获得金钱报酬,但却从研究中获得巨大的满足。
生物信息学
Sanger的论文发表后,基因序列研究迅速发展。一个主要的例子是BLAST(局部序列排比检索基本工具),它已经广泛被希望了解基因和蛋白质作用的生物学家所知晓。用户只需要在浏览器中打开程序,并插入一个DNA、RNA或蛋白质序列。几秒钟之后,它将显示来自数千生物体的相关序列,以及这些序列的功能信息,甚至有关的文献。有关BLAST的论文在排名中出现两次,分列第12位和第14位。
但由于引用习惯存在差异,BLAST被Clustal挤出排名。Clustal允许研究人员描述不同生物体的序列间的进化关系,以便找到看似无关的序列间的匹配关系,并预测基因或蛋白质的一个特定点的变化如何影响其功能。一篇发表于1994年的描述ClustalW的论文位列第10,另一篇发表于1997年的ClustalX论文位居第28。
BLAST和Clustal的研究小组在为其论文的排名展开竞赛。但Clustal研究小组成员、爱尔兰都柏林大学生物学家Des Higgins表示,这是友好竞赛。“BLAST是游戏规则改变者,它们获得的每一次引用都当之无愧。”
系统发生学
另一个受到日益发展的基因测序学鼓舞的是系统发生学。该学科致力于研究物种间的进化关系。
位居该排名第20位的是一篇介绍“邻位相连法”的论文——它根据遗传变异等进化距离的测量,将大量生物体快速有效地放置到系谱树上。上世纪80年代,人体人类学家Naruya Saitou在加盟得克萨斯大学Masatoshi Nei实验室后帮助设计了该技术。那时,人类进化和分子遗传学两个领域充斥着大量信息。“我们人体人类学者有点像面临着当时的大数据。”Saitou说。该技术帮助研究人员在不耗尽计算机资源的前提下,从大规模数据库中设计出系谱树。
位居第41的论文描述了如何将统计学运用到系统发生学中。1984年,华盛顿大学进化生物学家Joe Felsenstein改编了名为引导程序的统计学工具,以推断进化树不同部分的精确性。尽管一开始该论文积累引用数量十分缓慢,但到上世纪90年代至本世纪初,当分子生物学家意识到需要这样的方法进行预测后,它迅速受到欢迎。
统计学
芝加哥大学统计学家Stephen Stigler表示,尽管前100篇论文中有不少统计学文章,“但对我们统计学家而言,并非所有文章都是最重要的”。当然,它们已经被证明对广大科学家来说是最有用的。
这些交叉成功很多源于生物医学实验室不断得到的数据。例如,统计学论文中引用最频繁的一篇(位列第11)是1958年美国统计学家Edward Kaplan和Paul Meier发表的帮助研究人员了解一个人群的幸存模式的论文,例如临床试验的参与者。该方法引进了卡普兰-迈耶曲线。第二篇(第24位)则是英国统计学家David Cox于1972年发表的论文。他扩展了这些生存分析,纳入性别和年龄等因素。
而卡普兰-迈耶曲线论文则是名副其实的黑马,在上世纪70年代计算机技术兴起前,它几乎没被任何人引用。另外,简单和易用也推动该领域论文广受欢迎。英国统计学家Martin Bland和Douglas Altman因一项目前名为Bland Altman分析的技术而占据了排名的第29位。
最老和最新的统计学论文都涉及相同的问题——多重比较数据,但却出自迥然不同的科学背景。美国统计学家David Duncan在1955年发表的论文(第64位)适用于需要比较数个分组时,但排名第69位的控制错误发现率的论文(以色列统计学家Yoav Benjamini和Yosef Hochberg发表于1995年)则能被用于比较成千上万的数据,这一尺度是Duncan的论文无法达到的。
无论如何,耶鲁大学化学家Peter Moore表示,这位研究人员上了有力的一课。“如果引文是那些你想用的,发明一种能帮助人们进行自己希望的实验或让研究更加容易的方法,将比发现宇宙的秘密,让你走得更远。”
-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件