深度神经网络静态代码分析研究
近日,中国科学院软件研究所智能软件研究中心研究员武延军、吴敬征课题组在基于深度神经网络的静态代码分析研究中取得进展。课题组提出了基于多类型和多粒度的语义代码表示学习模型——MultiCode,解决了工业场景中涉及多需求的开发任务时面临的开发开销大、模型集成困难、可扩展性受限等问题,实现了在多需求工业场景下的高效开发和准确预测,在漏洞检测、代码克隆检测等任务中得到了具体实践,并获得实际应用。
基于深度神经网络的静态代码分析方法通常在不同代码分析任务中引入针对性设计,导致模型呈现高度多样化的态势。在工业领域,该现象会使开发者在开发涉及多需求的代码分析平台时,面临开发开销大、模型集成困难、可扩展性受限等问题。
针对上述问题,MultiCode模型能够学习代码中多种类型和粒度的语义信息,进而支撑多种代码分析任务。课题组提出使用抽象语法树、控制流图、程序依赖图等结构,对代码中不同类型和粒度的语义信息进行建模,并利用树神经网络和图神经网络分别对不同的语义信息进行处理。在该过程中,MultiCode模型自底向上地先学习语句级别的表示,再基于该表示学习代码段级别的表示。将该模型作为编码器进行神经网络构建,能够有效适配于不同的代码分析任务。在漏洞检测和代码克隆检测任务上的评估结果表明,其能够在不需要重新构建编码器的情况下,在不同任务中有效地识别并区分不同类别代码的语义,进而支撑多种任务上的预测。
相关研究成果以MultiCode: A Unified Code Analysis Framework based on Multi-type and Multi-granularity Semantic Learning为题,发表在软件可靠性工程国际会议(ISSRE 2021)的Industry Track上,并被评为最佳实践论文。研究工作得到国家重点研发计划、国家自然科学基金的支持。
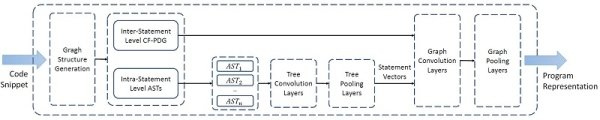
MultiCode基于多类型和多粒度的语义代码表示学习模型框架

ISSRE 2021最佳实践论文奖
-
仪器推荐

-
仪器推荐

-
仪器推荐

-
仪器推荐

-
仪器推荐
 询底价 Tel:400-6699-117 转 3777
询底价 Tel:400-6699-117 转 3777 -
标准