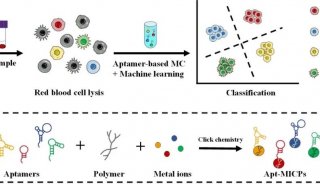
质谱流式技术及组织细胞群体深度解析方法概述
Data Driven Research: 组织细胞群体的深度解析
——神奇的质谱流式技术
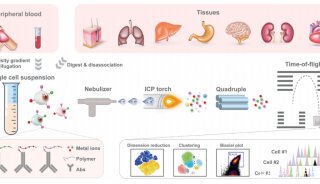
质谱流式是单细胞分析技术的一大突破,目前应用于血液、免疫、干细胞以及肿瘤等诸多研究领域。它创造性地使用了金属元素做为抗体的标签,利用ICP质谱实现了单细胞多参数的检测。金属标签具有极低的背景信号以及很好的标签化学稳定,结合ICP检测器的超高信号分辨能力,保证了质谱流式可以获得高质量的数据。由于检测通道数量已经达到几十个,质谱流式的数据中包含很大的信息量。
那么利用质谱流式平台获得的数据,我们究竟可以从中得到哪些信息呢?有该如何充分利用这些数据结果进行分析,提高单次实验的效率呢?事实上,不同的数据分析方法赋予了质谱流式不同的功能。这里,本文将就目前常见的一些数据分析方法及结果类型为大家进行简要的总结概述。
一、系统展示组织亚群构成以及功能、状态信息——Data Visualization
质谱流式数据包含所有被测细胞方方面面的信息,是地地道道的高维数据;这种数据的复杂性实际上是组织细胞本身异质性的忠实写照。获得这些数据后,科研人员首先想了解的其实就是组织的亚群构成情况。虽然数据中已经包含这样的信息,但是仍然需要经过加工处理才能转变为直观、易懂的图表,这一过程就是数据的可视化。
SPADE是一种常用的数据可视化方法。它首先将表型类似的细胞聚成小群,然后依照各小群的表型相似度进行聚类分析,最后得到一个树形图。SPADE树形图上每个节点(Node)都是由一群表型相似的细胞构成的,节点相对位置不同也体现了其表型的差异。因此,SPADE树形图直观展示出了组织细胞的亚群构成。
图一中展示的是不同时期的小鼠黑色素瘤中浸润的免疫细胞SPADE图谱,可以明显的看出单核细胞比例明显增大。

图一、小鼠黑色素瘤浸润淋巴细胞的亚群组成(利用32个表面标志分子进行SPADE分析图谱,数据来源:Salmon et al., 2016, Immunity 44, 924–938)
降维分析是另一类经常使用的数据处理方法,在尽可能保持信息不丢失的基础上,将多维信息压缩到二维;这样就可以用二维散点图来展示高维数据的结构了。常见的方法有viSNE、PCA等。
图二是根据16个胞外标志蛋白表达数据,对外周血白细胞进行viSNE分群结果。可以看出,在viSNE图谱中,几个主要免疫亚群各自聚群。同样,我们也可以以“热图”的方式展示不同刺激条件下pSTAT5在各个亚群中的变化情况。(Adeeb H et al, 2015)

图二、通过16个Marker对人外周血免疫细胞的viSNE分析图谱(数据来源:Adeeb H. Rahman,Cytometry Part A,Volume 89, Issue 6,2016)
除了SPADE和viSNE以外,数据可视化的方法还有很多,例如PCA、Scaffold Map FLOW-MAP等等;
二、比手工设门更精细的自动分群——Automated population identification
上述方法可以对在已有知识背景的前提下对已知表型的亚群进行直观数据分析,展示复杂的群体构成。而当关键亚群的表型是未知的,则需要一类可以充分挖掘质谱流式数据的自动分群方法。这种计算机自主的亚群分析方法叫做“DensVM”。
小鼠髓系细胞具有复杂的细胞组成,新加坡SIgN的研究人源利用质谱流式对不同组织来源的髓系细胞进行了检测,图三其viSNE分析结果。图中用不同颜色标记的是由计算机自动识别出的28个细胞亚群。B图中热图分析表明,这些亚群都具有不同的蛋白表达模式。很明显,相比图中手工识别的亚群(蓝色线框),这种计算机自动的分群方法要细致很多。例如,仅仅在Neutrophils(中性粒细胞)的蓝色线框内就识别出了5个表型不同的亚群。

图三、小鼠不同组织中髓系细胞的组成(A viSNE图谱;B 计算机识别的各个亚群的表型分析;数据来源Nat Immunol. 2014 Dec;15(12))
类似功能的分析方法还有很多,Accense、PhenoGraph等都是在质谱流式中经常使用的亚群分群方法。它们能够帮助我们识别在生理或病理情况下起到重要作用的细胞亚群、稀有亚群以及未知亚群。
三、精细解析细胞成熟、分化、去编程等动态过程——Cell development modelling
除了可以静态的分析组织细胞的亚群构成,质谱流式还可以对细胞分化、去编程等复杂的动态变化过程进行精细的分析。
我们以B细胞的在骨髓中的成熟过程为例说明该问题。我们知道,B细胞是在骨髓中发育成熟的,在骨髓样本中存在从造血干细胞(HSC)到Immature Naïve B之间各分化阶段的细胞;一般情况下,这些分化阶段没有绝对的界限,期间也存在大量的过渡状态的细胞,这就是B分化过程的连续性。
因此理论上讲,只要我们能检测足够多的骨髓细胞,就可以测得足够多的中间过渡状态的细胞,根据细胞表型的渐变我们就可以将这些细胞排列起来。这就是Wanderlust的分析基本思想,它让我们从单个骨髓样本获得细胞分化的动态信息。

图四、Wanderlust分析展示的人B细胞在骨髓中成熟过程
(数据来源:Sean C. Bendall等,Cell 157, 714–725)
Wanderlust会根据每个细胞排列的位置赋予给细胞一个Wanderlust值,其大小就反映了分化程度:0代表起点(造血干细胞),1代表终点(Immature Naïve B),该数值越小说明细胞越原始;
有了这个工具,我们可以观察B细胞分化过程中任意一个蛋白的表达变化,这些信息可以帮助我们找到分化过程中一些重要的事件。
对于一些in vitro的实验体系,我们可以利用更简单的方法观察细胞表型的变化过程。只需要将不同时间点的质谱流式数据放在做降维分析,得到的图谱就反映了细胞表型随时间的变化。图五中的Flow-MAP图谱中反映的是MEF细胞经过体外诱导成iPSC的全过程。颜色代表样本处理的时间长短,沿着由蓝色-黄色-红色的“时间轴”,我们可以看到MEF的去编程过程中细胞表型的变化过程。

图五、对MEF细胞的去编程过程的Flow-MAP分析
(数据来源:Eli R. Zunder等,Cell Stem Cell 16, 323–337)
四、量化分析信号通路分子之间的相互作用关系
质谱流式在信号通路的磷酸化蛋白的检测中表现卓越。一方面,它可以检测更多地信号通路分子,另一方面,相对于荧光基团,其抗体带有的金属标签稳定性有很大提升。我们知道,信号通路蛋白之间有比较复杂的相互作用关系,质谱流式可以将这种关系进行量化比较。
这里要用到的是一个名为DREVI的分析方法,它可以帮助我们从单细胞数据中提取出两个信号通路蛋白之间的“函数关系”,并用一系列参数对这种关系进行量化。下图I,II展示的是在不同的刺激条件下pCD3ζ和pSLP76之间的关系曲线。我们可以很容易看出,在第二种刺激条件下,较低的pCD3ζ水平就可以启动SLP76磷酸化,同时pSLP76也可以达到更高的水平。

图六、DREVI分析可以直观展示不同刺激条件下信号通路状态的改变
(数据来源:SmitaKrishnaswamy等,Science. 2014 November 28; 346(6213))
五、寻找具有临床指导意义的Bio-Marker
在比较贴近临床的研究中,我们往往需要对一系列病人样本和正常样本进行比较,找出病人样本特征。一般情况下,很难从整体蛋白表达水平找到具有统计学意义的差别,因为临床样本具有很大的异质性,比较有规律性、代表性的差别往往只存在于少数亚群中。前文提到,质谱流式可以将样本精细的分成很多亚群,因此它可以很方便的对这些亚群中相关蛋白的表达数据进行对比、相关性等统计学分析。
斯坦福大学的研究人员用质谱流式检测了多发性骨髓瘤病例和正常人外周血细胞39个蛋白的表达。为了寻找两组样本之间存在显著差异的Bio-Marker,他们引入了Citrus分析。首先通过其中的24个表面Marker聚类分成几十个亚群,然后通过对比各亚群中14个蛋白的表达,最终发现了图中所示的两个B细胞相关亚群(Cluster A 和Cluster B),在这两个亚群中,CD27在多发性骨髓瘤病人组的表达量要明显高于正常人。这一差异有希望做为该类疾病的一个BioMarker用于疾病的诊断。

图七、通过Citrus 分析识别出多发性骨髓瘤的特征性亚群
(数据来源:Leo Hansmann等,Cancer Immunol Res; 3(6) June 2015)
小结:数据驱动的研究方式,不断降低的技术门槛
可以看出,质谱流式数据分析具有很大的灵活性,研究者可以根据实验设计以及实验目的的不同,选择几种适合的分析方法结合使用,有效挖掘出需要的信息。这种研究方式也被称为数据驱动的研究(Data Driven Research)。
经过了几年的发展,质谱流式数据分析方法已经渐成体系。随着一些基于云的在线分析系统的出现,数据分析的技术门槛也大大降低。例如Cytobank,可以支持SPADE、viSNE以及Citrus等多种数据分析方法,软件界面也非常友好,研究人员只需要将数据上传到服务器,设定少数几个参数就可以完成这些分析。这也为质谱流式技术的普及创造了有利条件。