分享至
分享至



“数据跟着算力跑”到“算力围着数据转”的嬗变
“摩尔定律被打破后,什么将推动超级计算机性能的发展?”
12月13日,在今年的CCF HPC China 2022上,2021年度图灵奖获得者、来自美国田纳西大学和橡树岭国家实验室的杰克·唐加拉教授在演讲的最后,谈及HPC未来发展趋势,发出这样的提问。
一个跨时代的命题
这个问题的言外之意非常清楚:超算算力的发展以前主要依赖芯片性能提升,但如果芯片性能供不应求,还能依赖什么?
对这个问题,他也没有明确的答案。但他提到,HPC硬件厂商开发出先进设备,算法和软件就要不遗余力地去寻找使用新计算机的方法。
“向上的空间也很大”,杰克·唐加拉说:“人们可以在硬件的帮助下,通过软件和算法的改进来探索‘上面的空间’。”
问题的关键是,软件和算法如何改进,朝着什么方向改进?
早在2007年,1998年度图灵奖得主詹姆斯·格雷就在题为《科学方法的革命》的演讲中提出,随着数据的爆炸性增长,科学计算(即“第三范式”)中的数据密集型范式将成为一个独特的科学研究范式,即第四范式。而超算也将从科学计算工具,向着基于大数据、人工智能的“数据密集型科学”演进。
有评价称,詹姆斯·格雷提出的“第四范式”影响了至少一代计算人和科研人,人们开始认真审视海量数据与计算工具间的相互驱动。
与杰克·唐加拉同天演讲的中科院院士、北京航空航天大学教授钱德沛把问题讲得更直白:如今的应用“数据规模都很大,在分布式算力中心环境下,数据的放置对于应用的性能和能耗影响都很大”“在计算任务调度和迁移时,要充分考虑数据的传输和访问开销”。
超算最本质的是算力,而越来越多应用(如生物信息类)在付诸计算之前,更面临着数据激增的困扰。如今超算多采用异构架构,以让各类加速器发挥最大效用;但是异构存在着各类计算单元“各自为战”的问题……诸多矛盾,如何调和?
这个问题的一个答案是:面对非结构化的海量数据,多元异构的超算在呼唤“数据融合”。
一个校级超算的范例
目前,我国已建成了10个国家级超算中心,20多个人工智能计算中心,许多高校、企业和科研院所也自建了高性能计算系统。然而,有专家注意到,在不少的计算设施中,存储和网络这两大关键组件受到的关注度远远小于计算组件,以至于计算系统的性能只是“看上去很强”。
“现有的评价指标过于强调计算这个‘单科成绩’,而忽略了系统作为一个整体的表现,从而导致有的地方会设计出一套‘偏科系统’。”上海交通大学网络信息中心副主任、CCF高专委常务委员林新华在 CCF HPC China2022 上的发布活动中谈到,这样的“偏科系统”往往基准性能测试成绩很高,但在实际使用中性能却不好。
林新华带领的上海交通大学高性能计算团队早早针对这个跨时代的命题作出了有针对性的改变。
上海交通大学的“交我算”校级计算平台自2013年开始建设,秉承“普惠、融合”的建设理念,经过多年发展已建设成为国内高校领先的校级计算平台,具体包括云平台、人工智能计算平台、高性能计算平台等五大计算平台和科学大数据平台;并打造聚合门户,提供统一用户入口,为师生提供“互联网”化的计算服务。
门槛高企的超算应用变成了“互联网”化的计算服务,林新华介绍说:“原先三个月才能够完成的计算量,现依靠‘交我算’平台的超算集群仅需四天。”
面对纷繁复杂的计算需求,“交我算”是怎么做到如此高效的?
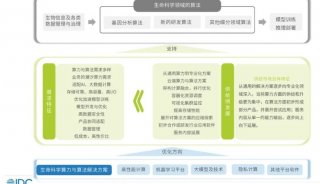
自2019年起,上海交通大学就与华为存储展开深度合作,共同打造“交我算”的数据密集型超算平台。基于华为 OceanStor,“交我算”构建了统一数据基座,将数据融合理念注入高性能计算。
凭借其长期在超算领域里的技术与应用创新积累,华为存储将其推出的OceanStor Pacific分布式存储产品作为“交我算”平台的存储池;林新华带领的交我算团队则进一步将这一存储池打造成统一的数据基座,支撑起“交我算”多种异构算力平台。
面对数据增长快、计算性能要求高、多元计算集群协调供给、存储成本高昂等数据困局,华为OceanStor Pacific分布式存储以出色的全对称分布式架构、容量与性能的线性增长,提供面向混合负载的高性能,并针对冷、热、温数据存放设计智能分级算法,灵活有效地管理数据全生命周期,逐一破解超算应用中对数据存储的多元诉求。
数据密集型超算异军突起
中科院院士、CCF HPC China2022大会名誉主席陈国良曾对计算应用中的数据量激增有个贴切的比喻。他说,如果说数据是数字世界的新石油,那么“预计到2025年占比将超过80%的非结构化数据”,就是石油中的“页岩油”。和页岩油一样,非结构化数据的“开采”(价值挖掘)难度更大,需要依赖更加专业化的工具。
陈院士口中的专业化工具,就包括“面向海量数据的高性能数据分析” (High Performance Data Analysis,HPDA)。映射到超算系统,就是数据密集型超算。
“交我算”即打造了一个典型的数据密集型超算范例。
“过去,是数据跟着算力跑。”林新华介绍说,为了应对复杂科学和工程问题的快速数值求解,过去半世纪来,业界更多关注的是如何打造最强大的算力,而承载数据的存储、网络设备仅作为算力的配套设施来考虑。而今,新兴应用的涌现、数据体量的剧增和数据安全问题凸显,让数据本身的价值愈发被广泛认可。
“融合AI、大数据等技术,以数据为中心,多元算力按需加持,传统超算已逐步演变成数据密集型超算,多种异构算力紧密围绕在同一个数据存储周围。”林新华说,随着数据密集型超算的异军突起,现在形势发生了反转:“算力围着数据转”。
“以数据为中心”也就是以价值为中心。“交我算”率先构建起的有统一数据基座的数据密集型超算平台,完成了对计算服务的提速。如林新华所说,从三个月到四天,计算的提速不仅大幅缩短用户的论文投稿周期,也大大降低科研人员的试错成本。
“重算力、轻存力”现状待改变
数据密集型超算,意味着场景应用中的数据分析处理乃至单纯的数据存储是“主角”。然而,从计算机效能视角出发,面对海量数据涌入,超算不能将大量机时浪费在等数据的读写上——这就是传统超算的“存储墙”难题。
据统计,我国存力与算力之比约为1:2,对应投资约为1:3;而美国这两组数据均为1:1。从数据作为新生产资料的角度来看,存力的基础地位日益彰显。要改变当前“重算力、轻存力”的现状,未来我国计算设施还要在存储基座上下功夫。
仍以“交我算”为例,“交我算”平台提供多种异构算力,拥有ARM集群、X86集群以及AI集群等,算力性能水平在全国名列前茅;同时“交我算”同时建有存储容量高达 35PB 的科学大数据平台,同样位居国内高校前列。从局外看,“交我算”的存算比相当可观。更重要的是,在众多集群下构建统一数据基座,可显著促进计算平台的全数据流动和数据融合,同时能为用户提供最大便利、释放算力和数据的最大价值。
这也更加佐证了,发展数据密集型超算,意味着超算的价值能够围绕数据应用的全流程计算去创造。
-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
政策法规