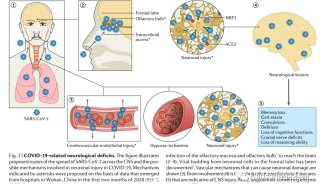
类脑信息处理研究取得进展

近期,中国科学院自动化研究所类脑智能研究中心类脑信息处理(BRAVE)研究组,在研究员张兆翔的带领下,在借鉴生物神经结构、认知机制与学习特性的神经网络建模与类人学习研究中取得了一系列突破性进展。该研究组在“视听模态的生成、融合”以及“智能体之间的知识迁移”取得了重大突破,系列成果发表在AAAI 2018上。
在“视听模态的融合”问题中,该研究组提出了有效将听觉信息融合在视频描述生成框架中的特征融合策略,并取得了理想的效果; 在“视听模态的生成”问题中,该研究组提出了一个跨模态循环对抗生成网络、一个联合对应对抗损失函数和一个动态多模态分类网络,构建出更有效的视听跨模态相互生成模型;在“智能体之间的知识迁移”问题中,该研究组将一种新类型的知识——交叉样本相似性引入到深度度量学习中,将知识形式化成一个教师和学生网络间的排序匹配问题,将经典的基于列的学习转换成排序学习算法,这一方法可大幅提高学生网络的性能,也可得到较传统方法更好的迁移性能。
1.视听模态的融合
视频描述生成在很多领域中有着潜在应用,比如人机交互、盲人辅助和视频检索。近些年来,受益于卷积神经网络CNN,递归神经网络和大规模的视频描述数据集,视频描述生成已经取得比较理想的结果。
大多数视频描述生成框架可以分为一个编码器和一个解码器,编码器对视频特征进行编码形成一个固定长度的视频特征向量,解码器基于该视频特征生成对应的视频描述子。研究者们针对定长的视频特征描述子提出了一些方法,比如对视频帧进行池化操作,下采样固定长度的视频帧,在递归网络视频特征编码阶段提取最后一个时刻的状态表示。
虽然上述方法均可生成比较合理的视频描述,但是这些模型的视频特征编码都只侧重于视觉信息而忽略了音频信息。该课题组认为,忽视声音模态会损害模型性能。比如,一个人躺在床上唱歌。大部分传统的视频描述生成方法只关注视觉信息而忽略声音信息,可能会产生语义不完整的句子:“一个人躺在床上”。如果可以将音频信息结合到模型中,就可以产生语义完整的句子“一个人躺在床上唱歌”。
那么如何更合理地利用视听觉信息?课题组提出并分析了三种视听觉特征深度融合框架,第一种为将视听觉信息简单并连在一起,第二种在视听特征编码阶段共享LSTM内部记忆单元,建立视听模态间的短时依赖性,第三种在视听特征编码阶段共享外部记忆单元,建立视听模态的长时依赖性。
同时,为了处理听觉模态缺失问题,课题组提出了一个动态多模态特征融合框架(如图2所示)。其核心模块为由一个编码器和一个解码器组成的听觉推理模型。听觉推理模型具体为将视觉特征输入编码器进行编码,利用解码器解码出对应的听觉特征,通过在生成的听觉特征与真实的听觉特征之间增加L2范数约束来更新该模型参数,并实现视觉特征到听觉特征的准确映射。模型在MSR-VTT、MSVD数据集上取得了理想的效果。
2.视听模态的生成
视听模态是视频中的两个共生模态,包含相同和互补信息。利用共同信息可实现模态间的相互转换。同时,互补信息可作为先验去辅助相关工作。因此,充分利用视听模态间的共同和互补信息可以进一步增强相关任务的性能。然而,由于环境干扰和传感器故障等因素,其中的一个模态会受损或者缺失,从而带来一些严重的问题,比如消音的影片或者模糊的屏幕。如果可以基于已知模态生成缺失模态,会给许多多媒体任务带来好处。因此,课题组致力于创建有效的视听跨模态相互生成模型。
传统的跨模态相互生成方法主要存在以下几个问题,一是模态间存在严重的结构、维度和信息不对称性,导致跨模态相互生成的质量不理想。二是模态间的相互生成是独立的,具有很大的不便性。三是其训练过程并不是端到端的。
为解决上述问题,课题组提出基于循环对抗生成网络的跨模态相互生成模型(CMCGAN)。
该模型包含四个子网络,分别为A-V(听觉到视觉),V-A(视觉到听觉),A-A(听觉到听觉)和V-V(视觉到视觉)子网络。每个子网络均由一个编码器和一个解码器组成。这四种子网络以对称的形式组成了两种生成路径,一种是V-A-V/A-V-A(视觉-听觉-视觉/听觉-视觉-听觉),另一种为跨模态生成路径A-A-V/V-V-A(听觉-听觉-视觉/视觉-视觉-听觉)。
受益于CMCGAN,课题组同时也提出了一个动态多模态分类网络。若输入有两个模态,则首先将它们进行融合然后输入到后续的分类网络中。若输入只有一个模态,则可基于CMCGAN生成缺失模态,然后将已知模态和缺失模态输入到后续的动态多模态分类网络中。在该研究中,研究组提出了一个跨模态循环对抗生成网络去实现跨模态的视听相互生成;提出了一个联合对应对抗损失函数将视听相互生成集成在一个统一的框架中,该损失函数不仅可以区分图像来自原始样本集还是生成集,而且可以判断(图像,声音)是否匹配;针对不同模态的输入,提出了一个动态多模态分类网络。
3.智能体之间的知识迁移
度量学习是许多计算机视觉任务的基础,包括人脸验证,行人再识别等。近年,基于度量损失函数指导的端到端深度度量学习取得了很大的成功。这些深度度量学习成功的关键因素是网络结构的强大。然而,随着所需表征特征的增强,网络结构变的更深更宽从而带来了严重的计算负担。在现实世界的许多应用如无人驾驶上,由于硬件资源的限制,使用这些网络会导致系统产生严重的延时。为保证安全性,这些系统需要实时的响应。因此,很难将最新的网络结构设计应用到该研究的系统中。
为缓解该问题,研究者们提出了许多模型加速的方法,可简单分为三类:网络剪枝,模型量化和知识迁移。网络剪枝迭代地删除对最后决策不太重要的神经元或权值。模型量化通过降低网络中权值和激活函数的表达准确性来增加了网络的吞吐量。知识迁移使用一个更大更强的老师网络去指导一个小的学生网络的学习过程。在这些方法中,基于知识迁移的方法是最具实际价值的。跟其他需要定制硬件或者实现细节的方法相比,知识迁移在没有额外开销的情况下也可得到相当的模型加速性能。
知识蒸馏和它的变体是知识迁移领域的核心方法。尽管它们所使用的知识形式不同,但都只针对于单个样本。也就是说,这些方法中的教师网络不管在分类层还是中间特征层都只为每个样本提供监督信息。所有这些方法均忽略了另外一种有价值的度量——不同样本之间的关系。这类知识同样编码了教师网络中所嵌入的空间结构。同时,该种知识所使用的实例水平的监督信息符合度量学习的目标。图4展示了研究组的动机。右上角展示了知识迁移后学生网络可以更好的捕捉图像相似性。数字0与6的相似性比数字3、4、5与6的相似性更大,因此等级更高。该研究中,课题组解决了以下几个问题:将一种新类型的知识——交叉样本相似性引入到深度度量学习中;将知识形式化成一个教师和学生网络间的排序匹配问题,将经典的基于列的学习转换成排序学习算法并致力于解决它;在不同度量学习任务上测试该方法,均可极大地提高学生网络的性能。另外,与目前的方法融合后可得到更好的迁移性能。
以上研究得到了国家自然科学基金、微软合作研究项目的资助。