外显子组测序(exome sequencing)是利用芯片或探针杂交富集外显子DNA序列,然后进行高通量测序的方法。由于疾病相关的突变大部分集中在 蛋白编码序列(开放读码框),且外显子只占基因组大小的1%,因此外显子组测序能够、较经济地、针对性地对基因区域进行扫描,鉴定外显子上与疾病相关的碱 基变异。该方法能够获得指定外显子捕获平台探针设计区域及侧翼200bp序列的遗传信息,极大地提高了人类基因组中外显子区域的研究效率,显著降低了研究 成本。外显子组测序主要用于识别和研究与疾病、种群进化相关的编码区及UTR区域内的结构变异。结合大量的公共数据库 提供的外显子数据,有利于更好地解释所得变异结构之间的关联和致病机理。目前,外显子组测序已广泛用于单基因病(孟德尔疾病)、癌症等复杂疾病的研究,成为鉴定致病突变、揭示疾病发生机制、提供诊断治疗参考的重要工具。 BioGenius 会针对项目需要采用Roche NimbleGen、Agilent和Illumina公司的捕获芯片富集全外显子组序列,并在Illumina公司的Hiseq2500高通量测序平台对外显子组捕获测序进行深度测序服务。
我们的技术优势- 高特异性:外显子区域覆盖全面,捕获特异性高。数据量充分,满足精准定位突变体基因
- 发现罕见变异:更深的覆盖度和更高的数据精确性,极大地提高了对稀有变异的检测能力。
- 高性价比:外显子区域的功能注释信息较为全面,且绝大部分疾病或性状相关的变异位于外显子区域,外显子组测序可更为经济有效的发现疾病或性状相关的变异,并结合公共数据库的注释信息方便开展变异序列的生物学意义研究。
- 针对遗传病或复杂疾病提供全面专业系统的生物信息分析服务
捕获技术方法简介-Roche NimbleGen外显子捕获产品
Roche NimbleGen外显子组捕获芯片包括两种不同的产品。SeqCap EZ Exome产品捕获区域达64 Mb,
SeqCap EZ Exome + UTR产品捕获区域达64 Mb + 32 Mb。
用于探针设计的数据库涵盖RefSeq, Vega, Gencode, Ensembl, CCDS和miRBase,可更全面的覆盖编码区序列,捕获效率更高,
可更为经济有效的发现更多的编码区序列变异。Nimblegen外显子组捕获产品支持多个样品混合进行捕获实验。
靶向捕获测序项目 实验流程

全面的生物信息学分析(含疾病突变数据库)
我公司采用基于经过深度优化的分析流程识别SNP/Indel 优势在于控制各类型假阳性错误,包括
1.可识别可能的PCR导致的错误
2.通过训练模型并依据单倍型质量得分(Haplotype Score)去除错误SNP
1.通过Inbreeding Coefficient过去所有杂合Het SNPs
2.根据测序链的偏差判定并过滤假阳性SNP
3.依据低质量区域(MQ resion)判定并过滤假阳性SNP
4.根据ReadPosRankSum指标过滤SNP
5.根据染色质端粒和着丝粒临近区域SNP的质量与特征过滤SNP
1. 基因组比对(BWA)
初步比对 (initial mapping)
重新比对 (refinement of the initial reads)
SNP-InDel识别 (multi-sample indel and SNP calling)
变异体的质量得分矫正(quality score recalibration)

2 突变体注释分析
突变体注释:1000G database, dbSNP, COSMIC, OMIM, HGMD(人类疾病数据库)等专业数据库的注释分析与过滤

•疾病数据库,变异体数据库包括:OMIM,CLINVAR,COSMIC,NCI60,ESP (exome sequencing project)
高级生物信息学分析还有提供:
1. 肿瘤基因组分析:Genome circos plot for mutations/SNV/SNP/INDEL 2. 肿瘤基因组外显子组测序分析-驱动基因预测
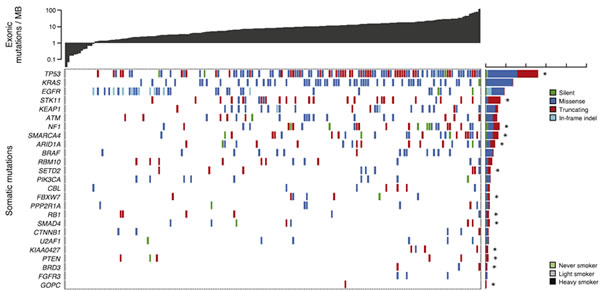
2. 肿瘤基因组外显子组测序分析-驱动基因预测
driver mutation prediction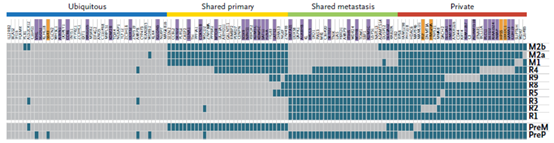
 3. 肿瘤起源进化分析
3. 肿瘤起源进化分析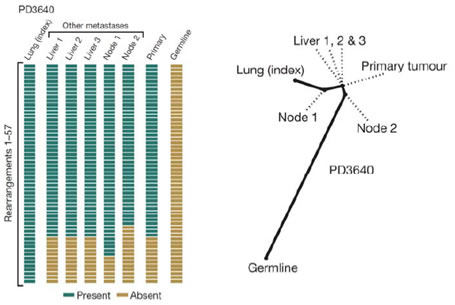 4 基于外显子靶向测序的 ctDNA 游离循环肿瘤DNA 测序
4 基于外显子靶向测序的 ctDNA 游离循环肿瘤DNA 测序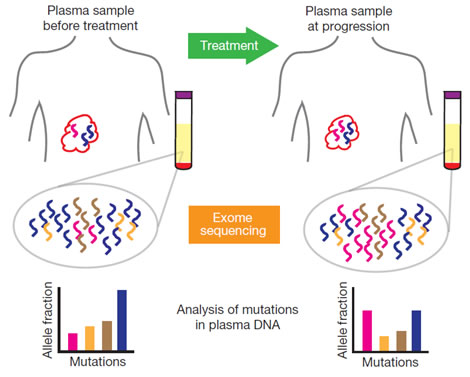
目前可以提供多组肿瘤特异基因标志物的 ctDNA技术服务(价格请电话咨询******:
| 产品类别 | 产品名称 | 基因数目 | 扩增片段 | 目标测序区域(bp) |
Solid tumors
实体肿瘤 | 肿瘤可诉性突变 Tumor Actionable Mutations | 8 | 118 | 7104 |
| 临床相关的肿瘤 Clinically Relevant Tumor | 24 | 602 | 39603 |
Hematologic malignancy
恶性血液病 | 髓系肿瘤 Myeloid Neoplasms | 50 | 2536 | 236319 |
Disease-specific
特异性疾病 | 乳腺癌 Breast Cancer | 44 | 2915 | 268621 |
| 结肠癌 Colorectal Cancer | 38 | 1954 | 182851 |
| 肝癌 Liver Cancer | 33 | 2052 | 191170 |
| 肺癌 Lung Cancer | 45 | 3586 | 332999 |
| 卵巢癌 Ovarian Cancer | 32 | 2021 | 198058 |
| 前列腺癌 Prostate Cancer | 32 | 1837 | 167195 |
| 胃癌 Gastric Cancer | 29 | 2377 | 222333 |
| 心肌症 Cardiomyopathy | 58 | 2657 | 249727 |
Comprehensive
综合检测产品组 | 遗传病携带突变检测 Carrier Testing | 157 | 6943 | 664735 |
| 癌易感性检测 Cancer Predisposition | 143 | 6582 | 620318 |
| 肿瘤综合筛查 Comprehensive Cancer | 160 | 7951 | 744835 |
针对外显子组测序结果识别到的突变位点的蛋白分子结构进行建模与模拟,分析突变体与WT结构差异,解读分析突变体蛋白功能改变。
 6 突变与生存期分析7 突变基因蛋白相互作用网络分析
6 突变与生存期分析7 突变基因蛋白相互作用网络分析 8
8 MHC靶向捕获测序
基于MHC靶向捕获测序技术分析MHC基因多态性 (HLA基因等)Nomenclature for Factors of the HLA System

分析策略-MHC/HLA haplotype 单倍型分析
•用途:用于Haplotype-based association
•分析原理:基于靶向捕获测序获得的数据通过比对数据库和de novo拼接的双重方式构建单倍型;通过一套打分系统筛选可信度高的MHC/HLA单倍型alleles
分析策略与步骤
测序数据准备(Read preparation)
质控与纠错 (Quality control and error correction)
数据库单倍型序列比对(IMGT/HLA database BLAST)
单倍型序列拼接(Haplotype sequence assemble )
单倍型可信度评分筛选(assembled haplotype sequence Typing)
分析可达到 4 digit resolution

•HLA Typing 分析原理
•HLA Genes Haplotype Sequences Assemble
•通过reads overlapping拼接exon的片段
•将比对片段与IMGT/HLA database比对过滤没有匹配的拼接片段序列
•通过比对的拼接序列(单倍体序列)通过打分对其可信度进行排序
•依据拼接的单倍体序列进行HLA Typing
•对所有拼接通过基本QC的片段进行Score(S)打分后,依据Tscore打分
•选择最可能的单倍体序列(通过Tscore=N打分对其可信度进行排序)
MHC/HLA haplotype 单倍型分析
•为了进一步保证HLA type 可靠度
•同时采用HLA calling算法•整合3种后验概率对每对HLA allele 进行分析
•
•(1) Pgenotype 概率(依据每碱基位置上的基因型)
•(2) Pphase 概率(依据同reads上临近vatiants的phase信息)
•(3) Pfrequency 概率 (依据不同allele的群体样本内频率)
•
•最后整合3种概率经过均一化给出最大后验概率对应的•HLA allele pairs( HLA types)





