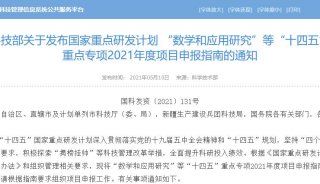
Elasticsearch性能优化指南(十四)
出现此拐点的分片数量取决于多种因素,包括:
可用的硬件
分片负载
数据量
针对集群执行的查询的类型
这些查询的发出率
正在查询的数据量
在生产环境硬件上,针对生产数据进行测试是校准最佳分片大小的唯一方法。通常使用数十GB的分片大小,这可能是进行实验的有用起点。当评估不同分片大小的影响时,Kibana的Elasticsearch监视功能可提供有用的历史集群性能视图。
为什么分片效率低下
每个segment都有需要保留在堆内存中的元数据。这些包括字段列表,文档数和term词典。随着分片的大小增加,其segment的大小通常也会增加,因为较小的segment会合并为较少的较大segment。通常,这可以减少给定数据量的分片的segment元数据所需的堆数量。分片至少应大于1GB,才能最有效地利用内存。
但是,即使一开始分片在1GB左右的内存效率上有所提高,但充满1GB分片的集群的性能仍可能会很差。这是因为拥有许多小分片也会对搜索和索引操作产生负面影响。每个查询或索引操作在要查询或建立索引的索引分片的单个线程中执行。接收到来自客户端的请求的节点将负责将该请求分配给适当的分片,并将这些单独分片的结果归并为单个响应。即使假设集群有足够的 search threadpool threads 可立即针对请求所需的所有分片进行请求的操作,但与向持有这些分片的节点发出网络请求以及必须合并许多小型结果相关的开销会导致分片延迟增加。这继而可能导致线程池耗尽,并因此导致吞吐量降低。
如何减少分片数量并增加分片大小
尝试使用这些方法来减少过度分片。
减少新索引的分片数量
您可以为使用create index API创建的新索引,指定index.number_of_shards设置,也可以为由索引生命周期管理(ILM)自动创建的索引,将它作为索引模板的一部分。
使用 rollover index API. rollover索引时,可以覆盖index.number_of_shards。
通过增加过渡阈值来创建更大的分片
您可以使用 rollover index API或通过在ILM策略中指定 rollover 操作来翻转索引。如果使用ILM策略,请增加rollover条件阈值(max_age,max_docs,max_size),以允许索引在过渡之前增长到更大的大小,这会创建更大的分片。
请特别注意任何空索引。由于满足max_age阈值,这些可以由滚动索引的ILM策略管理。在这种情况下,您可能需要调整策略以利用max_docs或max_size属性来防止创建这些空索引。一个可能发生这种情况的示例是一个或多个Beats停止发送数据。如果将这些Beats的ILM管理的索引配置为每天滚动,则每天将生成新的空索引。可以使用 cat count API.识别空索引。
通过使用跨越较长时间段的索引模式来创建更大的分片
创建涵盖更长时间段的索引可减少索引和分片数,同时增加索引大小。例如,您可以创建每月甚至每年的索引,而不是每日索引。
如果使用Logstash创建索引,则可以将Elasticsearch输出的index属性修改为涵盖较长时间段的日期数学表达式。例如,使用logstash-%{+ YYYY.MM}而非logstash-%{+ YYYY.MM.dd}创建月度索引,而不是每日索引。Beats还允许您更改在Elasticsearch输出的index属性中定义的日期数学表达式,例如Filebeat。
将现有索引缩小到更少的分片
您可以使用缩小索引API将现有索引缩小到更少的分片。
索引生命周期管理还可以在warm阶段对索引执行收缩操作。
重新索引现有索引以减少分片
您可以使用reindex API将现有索引重新分配到具有更少分片的新索引。重新索引数据后,可以删除过多分片的索引。
将索引从较短时期重新索引为较长时期
您可以使用reindex API将涵盖较短时间段的多个小索引重新索引为涵盖较长时间段的较大索引。例如,十月起的每日索引以及诸如foo-2019.10.11之类的命名模式可以合并为月度foo-2019.10索引,如下所示:
curl -X POST "localhost:9200/_reindex?pretty" -H 'Content-Type: application/json' -d'{"source": {"index": "foo-2019.10.*" },"dest": {"index": "foo-2019.10" }}'
-
政策法规
-
焦点事件
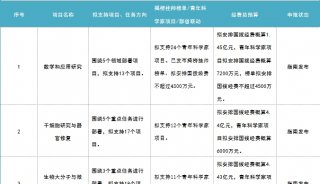
-
焦点事件

-
政策法规