Elasticsearch性能优化指南(一)
先了解相关读写原理
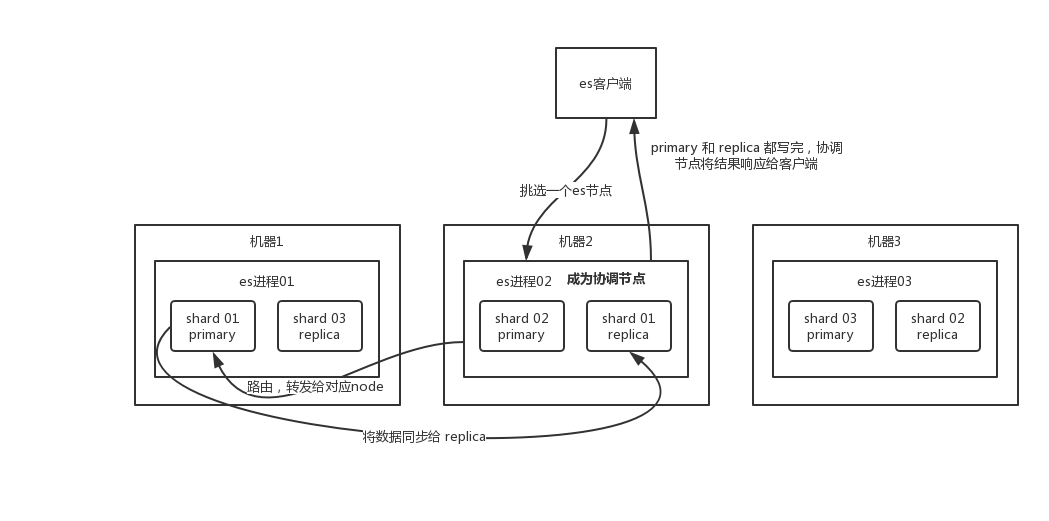
es 写数据过程
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node 。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
es 读数据过程
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node 。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
es 搜索数据过程
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊
java好难学啊
j2ee特别牛
你根据 java 关键词来搜索,将包含 java 的 document 给搜索出来。es 就会给你返回:java真好玩儿啊,java好难学啊。
客户端发送请求到一个 coordinate node 。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
-
政策法规