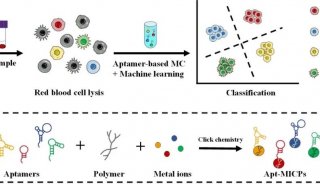
核酸适配体筛选实验的难点在哪里
首先它确实是比较难,但是SELEX实验的难和其它实验的难是不太一样的。像做单分子成像,或者某些超灵敏的检测类的实验,很多时候受制于我们的客观条件,受制我们所拥有的仪器设备。可是,核酸适配体的筛选与这些实验不同,因为SELEX实验它所用的仪器设备条件其实都非常简单,几乎所有的分子生物学实验室都具备。那么问题就来了,它的难到底难在什么地方?为什么看似简单的实验,大家会觉得很难呢?【当然,我也觉得挺难的】
我最开始接触SELEX实验的时候,我也不认为它难,直到做了几年之后,啥也没筛选出来的时候,才发现它真的不像我之前想象的那么简单,并不仅仅是那么几个简单的分子生物学实验完成了就可以的。它的难到底难在什么地方呢?不是难在这个实验操作上有多难,而是难在我们对这个实验的理解上。
关于筛选难这一点,我认为是大家可以想象到。如果说这个实验真的那么简单的话,那么为什么那么多人筛选不出来呢?不就是那么几个简单的分子生物学实验吗?所以这里面一定有它的原因。而这种原因,恰恰难在很大程度上,这种原因到现在还是未知的。也就是说,我们不知道为什么失败了,这才是真正难的地方。如果说我们知道我们为什么失败,由什么原因导致失败,那么我们去克服就可以了,我相信凭中国现在的实力,中国的研究条件和中国人的智慧没有什么能够难倒我们的。但是为什么这个事情让我们觉得很难,因为我们不知道,我们不明白,我们不理解其中的原因。
下面我想先说说,从我们实验室来说,我们觉得它难在什么地方?
核酸适配体筛选,其实可以分成两个大的部分,第一个部分主要是重复性的操作,一轮一轮的筛选实验。就是结合、分离、PCR扩增、单链制备、再筛选等等这样一个循环过程。我认为这部分实验对我们实验室来说,这部分不是大问题,我们能够保证正确的进行,而且这个时间的话,通常来说,如果是筛选一个单一的靶标,不管是小分子还是蛋白,我们基本上能够在两周之内完成全部筛选。如果稍微加快一些的话,基本可以在一周之内完成筛选过程。
对于我们来说,目前的难点在什么地方呢?主要是难在后期的鉴定。我们可以想象一下,在前面的筛选过程当中,我们可以从10的15次方的文库当中,找到那么几千条、几万条、或者几百条不同的序列构成的一个文库,这个文库如果是有亲和力的,说明前面筛选是成功的。但是获得这个文库之后,并不代表我们实验就已经成功了,我们还需要从这样一个文库当中去找到真正能够结合的单一序列,所以这个时候我们就要去做下一步的工作,需要去做测序,对测序结果进行分析,然后再做合成,再做进一步的鉴定,这步恰恰是我们目前的难点所在。
为什么说这一步是难点呢?因为我刚才说到了,前面的筛选过程,对我们实验室来说通常一个人需要1~2周的时间,而后面这个阶段,从测序、分析、挑选系列到合成,再到后面的鉴定要重复验证,而这个过程是非常的漫长,我们甚至需要两个月或三个月的时间才能够完成,而且后期的成本其实是高于前期成本的。
而且针对不同靶标这一部分的检测手段,差异性比较大。筛选时,筛选不同的小分子,我可以用类似的方法去筛选,但是我要去做亲和力检测时,很多时候不同的小分子、不同的靶标,需要用不同的方法,这也决定了后面整个实验的一个难度。
有很多人觉得后期的鉴定不就是一个例行的检测吗,例行的实验验证吗?为什么我们会觉得难呢?这边还有一个问题,我们在前面的筛选的时候,我们从10到15次方的文库得到很少的一些序列,比如说几万条这样一个文库,但是我们在做鉴定的时候,我们往往只能去合成及少量的序列,几条十几条或几十条这样的序列去做后期的验证。如果鉴定更多序列,成本很高,时间投入也很大。我们通过大量的高通量测序和无数个验证实验,发现那些高亲和力的序列,未必是那些富集率很高的序列。相反,那些富集程度很高的序列,往往并不见得是亲和力最高的,甚至它们根本没有亲和力。所以这给我们带来一个困扰,那就是我们到底该挑选哪些序列去做合成和验证呢?如果说我们仅仅是挑选那些富集程度高的话,我们极有可能会错过那些真正有价值的序列。
怎么能保证你不会错过有价值的适配体呢?那就是在你不了解的情况下,要尽可能多去合成一些序列。那么每多合成一条都会增加成本,而每多检测一个都会增加你后期实验的难度。所以这一步对我们来说是一个瓶颈,我们实验室目前的研究方向,在方法这一块主要是提升后续鉴定的通量,譬如通过单分子的方法,通过高超的测试方法,通过芯片的方法,通过流式的方法等等这一系列技术,这是我们目前关注的重点。
上面说道,我们实验室的前面做的比较快,后面是一个瓶颈,那是不是意味着我们现在所有的都能够筛选成功了呢?其实不是,我们实验室的筛选成功率尽管是相对比较高的,但是我们依然会面临很多失败的情况。这也是SELEX的难点所在。它难在什么地方,我想再做一点分析。
再回到刚开始我说的,为什么这些简单的分子生物学实验我们会失败呢?这里面其实因为整个筛选实验是一个长周期的实验,我们可能要筛选几周或者更长的时间。大家可以想象一下,当你去做一个实验,如果说你需要做很长时间,而中途你又不知道这个实验对还是不对,当你做了几周或者几个月之后,你发现你的实验失败了,那种感觉是非常令人沮丧的。而这个时候你怎么去分析原因呢?因为步骤很多,时间跨度很长,你甚至记不清楚开始是怎么做实验的,你甚至没有记下来开始用什么样的条件,所以这个时候你尽管失败了,你根本不知道失败在什么地方,你即便再去重复一次,你可能也很难找到失败的原因。所以,SELEX实验难的一个重要原因是它缺少一些中间过程的监测点,无法及时给你提供反馈,无法及时告诉你中间的实验步骤是对还是错。
你可能会想到,我筛选的时候去测亲和力不就可以了么?其实对于多数靶标的筛选来说,在早期的时候,在前面几轮的时候,你是根本看不到有任何亲和力的,那么这个时候你怎么去判断正确还是错误,是该继续还是该放弃呢?
这还没有一个非常好的方法,所以在过去的六七年的时间里,我们花了很大时间去建立这样一个监测指标,去判断筛选是否在朝正确道路上走。这就涉及到整个筛选进程的监测。
说到筛选进程监测这一块,其实也有不同的方法。基本的原理是两个,第一个就是检测结合的情况,是看看有没有亲和力,有没有比前一轮结合的更多一些,那这是一个非常重要的标准,这种方法的话也是比较重要的一个方法,也是比较客观的,但是有时候你还是找不到一个合适的方法,帮你去衡量它结合量多还是少。在这一部分我们一般使用结合比的方法来进行定量,就是每一轮我去观观测它结合比有没有提升。
另外一种监测筛选进程的方法是看每一轮获得文库的库容变化,就是随着筛选的进行库容是否在下降,按照一般的规律来说,随着筛选进程进行,你的库容会逐步降低,这也是一个判断指标。但是库容仅仅是一个参考指标,它不是一个筛选成败的金标准。也就是说你的库容如果在降低,说明正在富集,但它并不代表你的筛选是成功的。但是这种方法也有它的一个好处,就是可以帮助你判断筛选的终点。就是当你筛选几轮之后,你发现库容很小的时候,如果你依然检测不到亲和力,那么你就可以认为筛选是失败的。因为,当库容很低的时候,文库中的分子数非常少,如果还没有检测到有亲和力,极有可能在早期,高亲和力的分子被丢掉了。这个时候,你就可以果断放弃了。所以这种监测库容的方法,尽管它不能够明确告诉你,你的筛选是否正确,但是它可以帮助你去判断你是否该放弃还是该继续,所以这也是一个非常重要的指标,这个方法的话大家可以参考我们发表的文章(参考这里:https://pubs.rsc.org/en/content/articlehtml/2017/an/c7an01131h )。
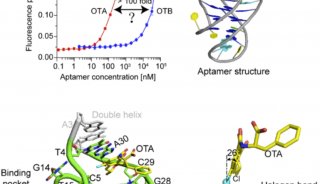
筛选真正难在什么地方呢?就是核酸适配体有很多机理性的问题没有搞清楚,举一个简单例子就是核酸适配体,它的结构会受它所处的溶液环境,pH值,离子强度,阳离子的种类等因素影响。这些都会影响到折叠,而折叠就会影响它的功能。但是这些因素怎么去影响的呢?到底会有什么样的影响?然后这些因素又会对结构带来什么样的变化,以及这种结构与功能的关系,这些方面研究还非常的欠缺,所以就导致我们在使用一个适配体的时候,当我们发现它的功能不能重现的时候,也许是它的结构折叠发生变化,但我们目前缺少非常灵敏的监测结构变化的手段。如果对于单个适配体来说,我们可以准备大量的样品,用CD来检测,也可以去结晶,或者做核磁。但是所有这些方法都是极其低效极其昂贵的。所以,如果从基础研究层面来说,核酸适配体筛选的难点来自于基础研究的欠缺,特别是结构与功能研究的欠缺,在往底层说,其实就是核酸结构研究手段的欠缺。
为什么这么说?我们可以看一下目前核酸结构的主要研究手段。主要X-ray晶体衍射,以及NMR,但是这两个手段目前都不太适合于研究核酸。譬如核磁,它只能研究比较小片段的核酸序列,目前的话通常在30个以下会比较容易研究,那X-ray的话, 如果核酸适配体不能够长出晶体的话,也很难去研究。核酸适配体结构具有一定的柔性,所以有些人会把它和它的靶标放在一起共结晶得到这个复合物晶体,然后再去解决结构,但是多数的核酸适配体很难去长出晶体来,这也导致绝大部分的核酸适配体没有结构信息,导致我们不知道它的结构是什么样的。目前另一个非常火热的研究大分子结构的手段,冷冻电镜技术。冷冻电镜目前它很难去做小分子的结构,而且核酸适配体它的结构是一个柔性的,所以即便是成像了也很难去做叠加分析,加上核酸适配体本身比较小,冷冻电镜也是无能为力的。所以目前三大主流研究结构的技术晶体衍射,核磁和冷冻电镜对核酸适配体都无能为力。正式因为这种底层的基础研究数据缺乏,导致我们对核酸适配体结构功能关系缺少深入的理解。当我们碰到问题的时候,我们很难从底层,从结构功能角度去做一些分析。这就是说真正基础性的研究欠缺,导致我们在筛选层面,以及在应用层面碰到很多问题的时候,我们不知道如何去解释。这方面,我们几乎无能为力,只能期待核酸结构研究技术早日获得突破。
核酸适配体技术从1990年建立以来经历了近30年,那么这30年过程当中,其实筛选方法一直在进步,但也没有突破性的进展,核酸适配体也没有像人们想象那样获得广泛的发展,整个产业依然是比较小众,那这个背后原因,其实真正的难点在于基础研究没有获得突破,导致筛选技术瓶颈没有突破。筛选出来的东西少了,能走到产业化应用阶段的就更少了。
我相信在未来的三五年,筛选技术一定会取得突破性的进展。筛选的适配体多了,有价值的也会多,能走到产业化阶段的也会多起来。产业生态才会慢慢建立,形成一个生态圈。我相信在未来3到5年之内,筛选技术筛选方法还会有很多新的技术建立起来,特别是高通量鉴定的方法,快速鉴定的方法。
其实筛选方法研究和结构功能研究,是相辅相成的。筛选到大量的适配体,有助于我们研究结构与功能,也可以让我们更好地理解结构与功能的关系。结构功能关系搞清楚了,可以更好地指导我们改进筛选方法。所以,这两者其实是一个相互促进的关系。
对于我们来说,我们比较擅长的还是做筛选技术研究,我们无法去做结构研究,所以我们会尽量提升筛选的成功率,建立高效的筛选方法,尽可能获得更多的优质的适配体。
简单总结一下,就是核酸适配体筛选困难,虽然它本身的技术并不复杂,难点是在于我们对整个核酸适配体缺少一些了解,而对它缺少了解,原因是基础研究的缺乏,基础研究的缺乏又源自研究手段的欠缺。
总之,筛选,依然很难。