
麦特绘谱生物科技(上海)有限公司

 分享至
分享至



公开课回顾 | 如何获取高质量代谢组学数据
点击上方蓝字关注“麦特绘谱”

2020年2月27日绘谱学堂第二期公开课--《如何获取高质量代谢组学数据》由麦特绘谱资深技术支持王洋博士主讲,本期公开课分别从样本类型如何选择、样本保存注意事项、样品前处理方法选择、样品检测过程中如何进行质控监测、如何进行代谢物准确鉴定及差异代谢物分析、生物学功能阐释常用数据库五个部分与大家分享麦特绘谱团队十几年代谢组学经验。本期参加课程的老师和同学们认真听讲并踊跃提问与交流。在此,小编特别整理了一份课后Q&A分享给大家,以便您随时温习查阅。
更多代谢组学研究方法欢迎咨询
Q&A
Q1. 贵公司Q300代谢芯片产品是基于LC-MS还是GC-MS平台开发?
A1:Q300代谢芯片产品是基于LC-MS/MS平台开发,目前已经在不同仪器厂家平台之间进行方法转移和优化。
Q2.下机数据如何进行数据预处理?
A2:仪器下机原始数据的预处理通常包括基线校正、去噪音、峰识别、峰提取、解卷积、峰对齐、积分峰面积(非靶向代谢组学)或峰面积根据准曲线计算浓度或折算成含量,根据检出率/QC等整理形成代谢物和样本的矩阵表格,再根据得到的数据矩阵表进行归一化、补空值(最小值十分之一等方法填补)得到预处理矩阵表。
Q3. 针对未知化合物,能具体说下通过几种角度来进行判断么?
A3:未知代谢物的鉴定分为两种,一种是Known Unknowns,一种是Unknown Unknowns。大部分做的还是前一种,即依赖于代谢物质谱库,对已知代谢物进行鉴定,库中有的才能鉴定出来,库中没有的只能标记为Unknown。目前,基于质谱的代谢物鉴定主要通过色谱和质谱两方面来确证。MSI(Metabolomics Standards Initiative) 将代谢物的鉴定分为四个层次:Level 1为Identified compounds,要求至少两种正交条件下用标准品验证,GC-MS要求保留时间或保留时间指数和质谱图与标准品一致,LC-MS要求保留时间、同位素分布和串联质谱图与标准品一致;Level 2为Putatively annotated compounds,即未经标准品验证,但质谱图与文献报告或数据库中的参考谱图一致;Level 3为Putatively characterized compound classes,即未经标准品验证,质谱图与已知同类物质相似;Level 4为Unknown compounds,即未知的代谢物。
Q4. 在非靶向代谢组中为什么选择氯苯丙氨酸作为内标,内标选择原则有哪些?
A4:内标物的选择是极其重要的,一般须满足以下几个条件:
(1)内标物与被分析物的物理化学性质相似(如:沸点、极性、化学结构等);
(2)内标物应是该试样中不存在的纯物质;
(3)它必须完全溶于被测样品(或溶剂)中,且不与被测样品发生化学反应;并与试样中各组分的色谱峰能完全分离;
(4)色谱峰的位置应与被测组分的色谱峰的位置相近,或在几个被测组分色谱峰中间,且又不共流出,目的是为了避免仪器的不稳定性所造成的灵敏度的差异;
(5)选择合适的内标物加入量,以免由于它们处在不同响应值区域而导致的灵敏度偏差。
(6)氯苯丙氨酸更适用于人及动物源类生物样本作为内标选择,而植物样本常用核糖醇作为内标,研究者应根据样本类型选择适宜的内标。
Q5. 同一批数据用不同软件进行分析,最终结果会有差别吗?
A5:不同软件之间获得的结果肯定有一定差别,因为处理的参数、方式存在一定区别,但最终结果整体差别不大。
Q6. 非靶向代谢组学用QC做质控,为什么还必须要加入内标?
A6:QC质控主要的作用检测仪器系统方法稳定性,客观地评价大规模样本批次内的重复性,以及矫正批间的误差。内标的作用既可以辅助监测仪器系统稳定性,又能在数据处理时用于内标归一化。
Q7. 请问找到差异代谢物后,又怎么处理呢?
A7:根据筛选出的差异代谢物,可以从以下几个研究思路开展(供参考):
(1)差异代谢物进行通路富集分析,富集到显著变化的代谢通路,锁定差异代谢物上下调变化情况及上下游代谢物、相关作用的酶即蛋白,验证酶的变化情况是否与代谢物的变化相一致。
(2)根据差异代谢物的筛选指标P值、FC(Fold change)值、VIP值,先关注P值越小、变化倍数越大(FC的异常大和异常小)、VIP值越大的差异代谢物,对这部分代谢物进行相关生物学功能文献调研,当生物学功能比较明确时,可以此为发现集数据进一步选择其他中心临床大样本集、相关疾病模型的动物水平样本、细胞水平样本等开展多水平的验证性试验,当显著的差异代谢物在临床大样本集得到确认后可进行ROC等分析进一步筛选潜在生物标志物。
(3)差异代谢物和其他组学(基因组、转录组、蛋白组、菌群16S、临床指标)筛选到的差异基因、差异蛋白、差异菌群和临床指标等做关联分析,看是否能映射到相同通路,解释相同的生物学功能。
(4)根据筛选到的差异代谢物进一步开展靶向定量代谢组学的确认,同位素示踪或代谢流试验的代谢流向确定,从而阐释生物学意义。
Q8. 单维统计分析数据结果是否需要校正,如何校正?
A8:因为代谢组学一次要比较几十到数百种代谢物,如果以0.05作为显著性水平时,原本每次分析比较出现I类错误(假阳性)的概率为0.05,不出现I类错误的概率为0.95,当同时汇报N种代谢物时,所有代谢物都不出现I类错误的概率降低为0.95N,此时出现I类错误的概率上升为1-0.95N。因此,若代谢物数目较多时,有的审稿人会要求采取p值校正。p值校正有很多种方法,如采用Bonferroni correction、Holm correction、 False discovery rate (FDR) 校正等。Bonferroni校正由于过于严格,较难发现阳性结果,因此较少使用,FDR校正可以控制I类错误,且校正较为温和,在代谢组学在内的多种学科领域均被广泛接受,因此,如需对p值进行校正,推荐使用FDR校正。
Q9. 代谢组学应如何设置生物学重复数?
Q9:通常情况下细胞/微生物样本每组至少6个生物学重复,建议8个以上重复;模式动物/植物样本每组至少10个生物学重复;临床样本一般每组50个生物学重复(严格控制患者入组条件是获得高质量数据的前提,特别提醒临床疾病样本的遴选)。样本重复数强烈建议大于6个,组内样本数量过少,多维统计分析时模型容易过拟合。
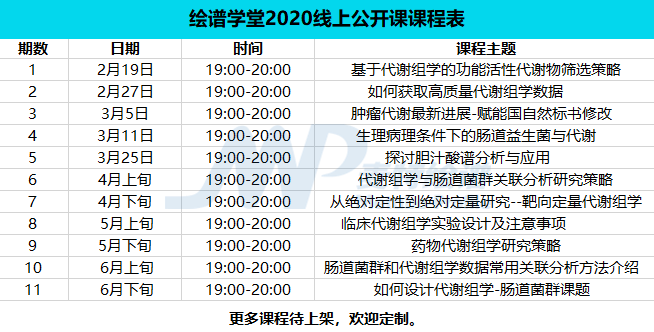
绘谱学堂线上课程安排

精彩回顾
5. 公开课回顾 | 血清游离脂肪酸在个体发生代谢异常的重要作用
6. 公开课回顾 | 胆汁酸全谱分析在临床应用中的探索与案例分析
7. 公开课回顾 | 肠道菌群和宿主代谢组学相关性研究的分析策略
9. 公开课回顾 | 糖代谢重编程在急性髓细胞白血病恶性进展中的作用及糖代谢抑制剂药物的开发

解锁更多精彩「代谢组学」相关资讯!
微信公众号:麦特绘谱
Tel:400-867-2686
Web: www.metaboprofile.com
识别二维码,关注我们
-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章
-
微信文章
-
微信文章

-
微信文章
-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章
-
微信文章

-
微信文章

