

 分享至
分享至



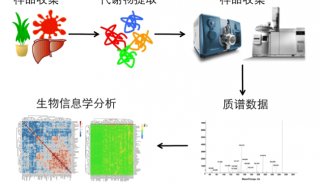
高质量代谢组学数据库的建立和验证

代谢组学的飞速发展,尤其是分析技术的进步、样本数量的增加、样本类型的多样化以及多检测平台的联合应用,使代谢组数据在数量和复杂性上急剧增加。代谢组学数据库的开发对于归纳总结这些大数据、提高数据的使用率、进行深层次的交叉分析以及揭示隐藏在大数据背后的生物学机理都有重要的作用。同样,当标准品数据库不够大或信息不完善,化合物相关的信息输入到该数据库中,便很有可能输出不准确的鉴定结果,导致代谢物的鉴定不准确,那么基于该鉴定结果的后续分析也是徒劳。目前代谢组学界达成共识的化合物鉴定等级分为5级(图1):
Level 1:参考标准品在相同分析条件下确证的化合物,包括匹配保留时间(RT)、一级(MS1)和二级(MS2),这是唯一被认为是确证的代谢物鉴定等级;
Level 2:通过文献/公共库检索所得或者可能的断裂方式推测所得化合物;
Level 3:根据某类化合物的特定碎片所推断的一类化合物;
Level 4:为根据质谱信息(加和离子、同位素峰、碎片信息等)推测出分子式的化合物;
Level 5:为分离得到、有精确质荷比(m/z)且感兴趣的未知化合物。

图1. 代谢组学化合物鉴定等级分类
较基于公共库或参考文献的Level 2鉴定,基于自建标准品库的Level 1鉴定有两大优势(1)避免使用的仪器平台的多样性、分析方法的差异性,仪器的背景噪声的区别、液相体系的不同,导致所获得的谱图差异;(2)增加保留时间(RT)作为参考标准,在实际代谢物鉴定过程中,将样本检测所得的二级谱图与公共库进行比对时,会存在“一对多”情况,从而增加了鉴定结果的假阳率,而自建库Level 1的鉴定结果,是经过RT匹配的,因此Level 1的鉴定更准确,假阳率更低。
为了准确鉴定代谢物,降低代谢物鉴定假阳率,全面提升不同类型生物样本的代谢物鉴定数量,氨探生物从“库建立”和“库验证”两大角度建立了标准品数据库搭建全流程,使化合物Level 1 鉴定数量全面提升(图2)。

图2. 标准品建库全流程
标准品建库流程:
即指标准品采购清单的确定、标准品基本信息收集、标准品储藏、称量配制、标准品检测及标准品mzVault建库步。
(1)标准品采购清单的确定:标准品的采购并非随意为之,采购依据主要包括高分文献报道、机器学习筛选和注释频率较高Level 2代谢物。
(2)标准品基本信息收集:收集HMDB Name、Compound ID、CAS No等,表1以Creatinine为例,列举了标准品所需收集的相关信息。
表 1 Creatinine标准品相关信息
HMDB Name | HMDB ID | Compound ID | CAS No | Formula | M+H | M-H |
Creatinine | HMDB0000562 | C00791 | 60-27-5 | C4H7N3O | 114.06619 | 112.05164 |
(3)标准品的储藏、称量配制:该步骤是建库流程里最简单最基础的操作,但却是最耗时,最繁琐的环节。不仅要确保标准品均被储藏最佳条件,还要清楚的记录并管理每个标准品储藏位置,方便后期取用。每个标准品采购回来,均会被赋予唯一编号,并根据其极性和化学性质选择不同的溶剂。
表 2 标准品配制标准
标准品形态 | 标示量 | 称取量 | 总体积 | 终浓度 |
固体粉末 | ≥ 20mg | 5mg | 1mL | 5mg/mL |
固体粉末 | < 20mg | 整瓶溶解 | 1mL | 5mg/mL |
液体 | 单位为体积单位 | 0.1mL | 1mL | 稀释10倍 |
液体 | 单位为重量单位 | 5mg | 1mL | 5mg/mL |
(4)标准品检测:首先要根据其准确分子式使用Xcalibur软件计算精确的M+H、M-H值编辑仪器方法,并且使用C18及HILIC不同类型的色谱柱进行正负两种模式的检测,设定多个碰撞能量,确保不同性质的标准品均被成功建库,使得化合物的碎片和谱图库更为完整和丰富。
(5)标准品mzVault建库:将原始文件导入mzVault软件对应标准品下进行手动图谱导入,最终对每个标准品进行mol结构的补充和保留时间的归一化。
标准品库验证流程:
(1)标准品数据库原始文件与新建数据库的匹配,相当于一种“自证”的过程,源于标准品原始文件的数据库,再去对标准品进行注释,可以检查建库过程中原始文件和谱图导入有无失误,其次可以检查数据库的质量。
(2)基于不同类型生物样本的数据库验证流程,对每次更新的标准品数据库的最终考量。数据库最终是服务于项目的,不同类型生物样本代谢物鉴定数量的稳定提升才是数据库不断更新的最终目标。
准确收集标准品的相关基本信息,是建库工作顺利推进的前提,而标准品库的成功验证又是衡量其是否可以最终用于代谢物注释的标准。氨探生物深谙做代谢组学不难,而难在做好代谢组学的道理,始终以高水平、高标准、高投入为标准,致力于建立一个高质量的自建代谢物标准品数据库,提高代谢物鉴定的准确性。
如果您对我们的产品感兴趣,或者有宝贵的意见和建议,请联系我们:info@untangledbio.com。
1. Identifying small molecules via high resolution mass spectrometry: communicating confidence. Environ Sci Technol. 2014 Feb 18;48(4):2097-8.
2. Establishment of a High Throughput MS Database and Its Application in Endogenous Metabolite Metabolomics Profiling. High-throughput Screening Protocol eBook. Bio-101: e1010847.
解构健康奥秘、探寻生命答案,氨探生物以一流的分子表型组平台和成熟的临床转化应用体系,为优秀的研究团队进行技术和数据赋能,致力于实现分子表型水平的精准诊疗。

-
仪器推荐
-
仪器推荐

-
仪器推荐

-
仪器推荐

-
仪器推荐
-
微信文章
-
微信文章

-
微信文章

-
微信文章
-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章

-
微信文章
-
微信文章
-
微信文章

-
微信文章






