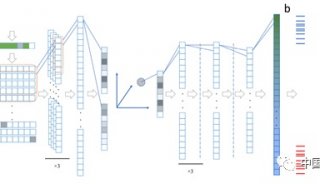
相比GPU和GPP:FPGA才是深度学习的未来?(二)
除了编译时间外,吸引偏好上层编程语言的研究人员和应用科学家来开发FPGA的问题尤为艰难。虽然能流利使用一种软件语言常常意味着可以轻松地学习另一种软件语言,但对于硬件语言翻译技能来说却非如此。针对FPGA最常用的语言是Verilog和VHDL,两者均为硬件描述语言(HDL)。这些语言和传统的软件语言之间的主要区别是,HDL只是单纯描述硬件,而例如C语言等软件语言则描述顺序指令,并无需了解硬件层面的执行细节。有效地描述硬件需要对数字化设计和电路的专业知识,尽管一些下层的实现决定可以留给自动合成工具去实现,但往往无法达到高效的设计。因此,研究人员和应用科学家倾向于选择软件设计,因其已经非常成熟,拥有大量抽象和便利的分类来提高程序员的效率。这些趋势使得FPGA领域目前更加青睐高度抽象化的设计工具。
3、FPGA深度学习研究里程碑:
1987VHDL成为IEEE标准
1992GANGLION成为首个FPGA神经网络硬件实现项目(Cox et al.)
1994Synopsys推出第一代FPGA行为综合方案
1996VIP成为首个FPGA的CNN实现方案(Cloutier et al.)
2005FPGA市场价值接近20亿美元
2006首次利用BP算法在FPGA上实现5 GOPS的处理能力
2011Altera推出OpenCL,支持FPGA
出现大规模的基于FPGA的CNN算法研究(Farabet et al.)
2016在微软Catapult项目的基础上,出现基于FPGA的数据中心CNN算法加速(Ovtcharov et al.)
4. 未来展望
深度学习的未来不管是就FPGA还是总体而言,主要取决于可扩展性。要让这些技术成功解决未来的问题,必须要拓展到能够支持飞速增长的数据规模和架构。FPGA技术正在适应这一趋势,而硬件正朝着更大内存、更少的特征点数量、更好的互连性发展,来适应FPGA多重配置。英特尔收购了Altera,IBM与Xilinx合作,都昭示着FPGA领域的变革,未来也可能很快看到FPGA与个人应用和数据中心应用的整合。另外,算法设计工具可能朝着进一步抽象化和体验软件化的方向发展,从而吸引更广技术范围的用户。
4.1. 常用深度学习软件工具
在深度学习最常用的软件工具中,有些工具已经在支持CUDA的同时,认识到支持OpenCL的必要性。这将使得FPGA更容易实现深度学习的目的。虽然据我们所知,目前没有任何深度学习工具明确表示支持FPGA,不过下面的表格列出了哪些工具正朝支持OpenCL方向发展:
Caffe,由伯克利视觉与学习中心开发,其GreenTea项目对OpenCL提供非正式支持。Caffe另有支持OpenCL的AMD版本。
Torch,基于Lua语言的科学计算框架,使用范围广,其项目CLTorch对OpenCL提供非正式支持。
Theano,由蒙特利尔大学开发,其正在研发的gpuarray后端对OpenCL提供非正式支持。
DeepCL,由Hugh Perkins开发的OpenCL库,用于训练卷积神经网络。
对于刚进入此领域、希望选择工具的人来说,我们的建议是从Caffe开始,因为它十分常用,支持性好,用户界面简单。利用Caffe的model zoo库,也很容易用预先训练好的模型进行试验。
4.2. 增加训练自由度
有人或许以为训练机器学习算法的过程是完全自动的,实际上有一些超参数需要调整。对于深度学习尤为如此,模型在参数量上的复杂程度经常伴随着大量可能的超参数组合。可以调整的超参数包括训练迭代次数、学习速率、批梯度尺寸、隐藏单元数和层数等等。调整这些参数,等于在所有可能的模型中,挑选最适用于某个问题的模型。传统做法中,超参数的设置要么依照经验,要么根据系统网格搜索或更有效的随机搜索来进行。最近研究者转向了适应性的方法,用超参数调整的尝试结果为配置依据。其中,贝叶斯优化是最常用的方法。
不管用何种方法调整超参数,目前利用固定架构的训练流程在某种程度上局限了模型的可能性,也就是说,我们或许只在所有的解决方案中管窥了一部分。固定架构让模型内的超参数设置探究变得很容易(比如,隐藏单元数、层数等),但去探索不同模型间的参数设置变得很难(比如,模型类别的不同),因为如果要就一个并不简单符合某个固定架构的模型来进行训练,就可能要花很长时间。相反,FPGA灵活的架构,可能更适合上述优化类型,因为用FPGA能编写一个完全不同的硬件架构并在运行时加速。
4.3. Low power compute clusters低耗能计算节点集群
深度学习模型最让人着迷的就是其拓展能力。不管是为了从数据中发现复杂的高层特征,还是为数据中心应用提升性能,深度学习技术经常在多节点计算基础架构间进行拓展。目前的解决方案使用具备Infiniband互连技术的GPU集群和MPI,从而实现上层的并行计算能力和节点间数据的快速传输。然而,当大规模应用的负载越来越各不相同,使用FPGA可能会是更优的方法。FPGA的可编程行允许系统根据应用和负载进行重新配置,同时FPGA的能耗比高,有助于下一代数据中心降低成本。