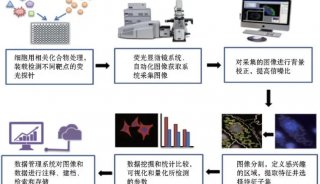
如何进行变量筛选和特征选择
交叉验证是机器学习中常用的一种验证和选择模型的方法,常用的交叉验证方法是K折交叉验证。将原始数据分成K组(一般是均分),将每个子集分别作一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,k个模型的验证误差的均值即作为模型的总体验证误差,取多次验证的平均值作为验证结果,误差小的模型则为最优模型。k一般大于等于2,一般而言 k=10 (作为一个经验参数)算是相当足够了。
采用的R包是bestglm,主要函数是bestglm()。
结合一个二元Logistic回归的例子,分享如何运用R软件实现10折交叉验证。
搭建完模型,运用predict()得到预测概率,保存测试集的预测概率。
函数中IC = "CV"表示采用交叉验证,CVArgs 表示交叉验证的参数,k=10表示分成10份,REP=1是每次一份作为测试集,family=binomial 表示因变量为二项分布。该函数是利用最优子集回归的原理,对于不同数量的特征,都用k折交叉验证法求一个验证误差,最后比较验证误差与特征数量的关系,选取最优变量。
将返回结果的cv列作图,可以看到在模型变量个数为3的时候,验证误差变得很小,之后随着变量个数增加,误差变化不大。利用coef()函数可查看最优变量。
根据筛选的最优变量,搭建模型,运用predict()得到预测概率。
根据ROC曲线面积对比两个模型在测试集上的预测性能,检验P值>0.05,且AUC均接近于1,说明两模型预测性能一致且很好,但交叉验证得到的模型变量为3个,模型简洁,在实际运用中效率更高,因此可选择交叉验证的模型作为最优模型。
在构建模型做变量筛选方法比较多,在前面推文中给大家介绍了2个,可以翻看一下
如何进行高维变量筛选和特征选择(一)?Lasso回归
如何进行变量筛选和特征选择(二)?最优子集回归