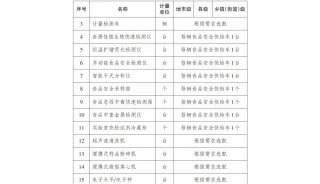
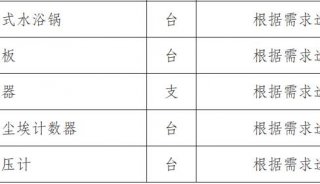
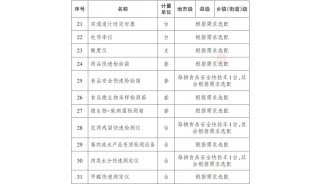
什么是散列表(Hash Table)
散列表(Hash table,也叫哈希表) ,是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 到首字母 的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则 ,存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
为了知道冲突产生的相同散列函数地址所对应的关键字,必须选用另外的散列函数,或者对冲突结果进行处理,而不发生冲突的可能性是非常之小的,所以通常对冲突进行处理。常用方法有以下几种:
开放寻址法(open addressing) 。想象一下,有一趟对号入座的火车,假设它只有一节车厢,上来一位坐7号座位的旅客。过了一会儿,又上来一位旅客,他买到的是一张假票,也是7号座位,这时怎么办呢?列车长想了想,让拿假票的旅客去坐8号座位。过了一会儿,应该坐8号座位的旅客上来了,列车长对他说8号座位已经有人了,你去坐9号座位吧。哦?9号早就有人了?10号也有人了?那你去坐11号吧。可以想见,越到后来,当空座越来越少时,碰撞的几率就越大,寻找空座愈发地费劲。但是,如果是火车的上座率只有50%或者更少的情况呢?也许真正坐8号座位的乘客永远不会上车,那么让拿假票的乘客坐8号座位就是一个很好的策略了。所以,这是一个 空间换时间 的游戏。玩好这个游戏的关键是,让旅客分散地坐在车厢里。如何才能做到这一点呢?答案是,对于每位不同的旅客使用不同的探查序列。例如,对于旅客 A,探查座位 7,8,23,56……直到找到一个空位;对于旅客B,探查座位 25,66,77,1,3……直到找到一个空位。如果有 m 个座位,每位旅客可以使用 的 个排列中的一个。
显而易见,最好减少两个旅客使用相同的探查序列的情况。也就是说,希望把每位旅客尽量分散地映射到 m! 种探查序列上。换句话说,理想状态下,如果能够让每个上车的旅客,使用 个探查序列中的任意一个的可能性是相同的,我们就说实现了一致散列。(这里没有用“随机”这个词儿,因为实际是不可能随机取一个探查序列的,因为在查找这名旅客时还要使用相同的探查序列)。
真正的一致散列是难以实现的,实践中,常常采用它的一些近似方法。常用的产生探查序列的方法有: 线性探查,平方探测,以及双重散列探查 。这些方法都不能实现一致散列,因为它们能产生的不同探查序列数都不超过 个(一致散列要求有 个探查序列)。在这三种方法中,双重散列能产生的探查序列数最多,因而能给出最好的结果。
显示线性探测填装一个散列表的过程:
关键字为{89,18,49,58,69}插入到一个散列表中的情况。此时线性探测的方法是取 。并假定取关键字除以10的余数为散列函数法则。
第二次冲突则发生在58上,取 ,往下查找3个单位,将58填装在地址为1的空单元。69同理。
表的大小选取至关重要,此处选取10作为大小,发生冲突的几率就比选择质数11作为大小的可能性大。越是质数,mod取余就越可能均匀分布在表的各处。
聚集(Cluster,也翻译做“堆积”)的意思是,在函数地址的表中,散列函数的结果不均匀地占据表的单元,形成区块,造成线性探测产生一次聚集(primary clustering)和平方探测的二次聚集(secondary clustering),散列到区块中的任何关键字需要查找多次试选单元才能插入表中,解决冲突,造成时间浪费。对于开放定址法,聚集会造成性能的灾难性损失,是必须避免的。
-
项目成果
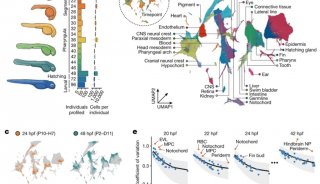
-
焦点事件

-
项目成果

-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件
-
实验室动态

-
科技前沿

-
焦点事件
-
科技前沿

-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件

-
项目成果

-
焦点事件

-
焦点事件

-
焦点事件
-
项目成果
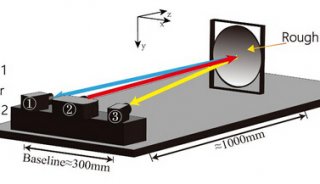
-
焦点事件

-
焦点事件

-
焦点事件

-
科技前沿

-
产品技术

-
焦点事件