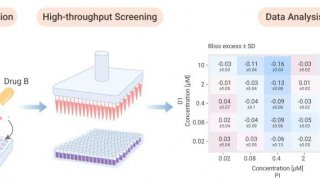
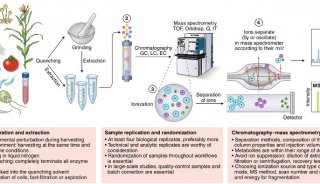
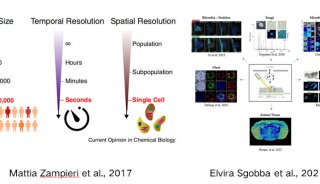
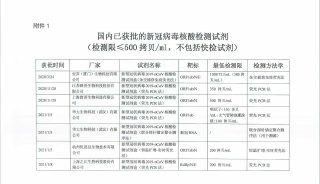
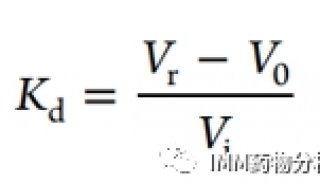毕文健等开发针对大样本两基因组分析的算法——SPAGE
复杂疾病的发生与发展不能完全由遗传变异来解释,而是遗传变异和环境因素共同作用的结果。基于关联分析找出基因与环境的交互作用(GxE effect)有助于我们了解疾病的发病机制和设计个体化治疗方案。但是这种交互作用的关联性较弱,因此常常需要较大的数据样本才能达到足够的检验效能。最近几年,随着测序技术和电子健康记录(Electroic Health Record, EHR)的发展,很多大型的生物样本资源库(Biobank)为研究者提供了非常详尽的大样本信息。比如UK-Biobank就收集了50万个样本的全基因组DNA测序信息,疾病诊断信息,以及环境因素信息。这使得我们可以在全基因组(genome-wide)乃至于全表型组(phenome-wide)尺度下进行基因与环境的交互作用(GxE)关联分析。然而,样本量的大量增长对全基因组关联分析算法的运算速度提出了更严苛的要求。比如,当分析40万样本数据时,一次逻辑回归(logistic regression)大约需要1.7秒,而几百万次逻辑回归则需要数月的运算时间。因此我们必须设计新的算法来进行大样本量下的全基因组GxE分析。
2019年11月14日,密歇根大学Seunggeun Lee团队(第一作者为毕文健博士)在The American Journal of Human Genetics杂志上发表文章A Fast and Accurate Method for Genome-Wide Scale Phenome-Wide G x E Analysis and Its Application to UK Biobank,提出了一个针对于大样本量全基因组GxE 分析的新算法SPAGE。

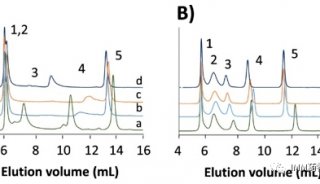
该算法利用条件期望构造了一种新的Score统计量并利用鞍点逼近法(saddlepoint approximation)来计算统计p值。对于一次全基因组GxE分析,SPAGE只需要在零假设下进行一次逻辑回归,这极大提升了运算速度。数值模拟结果显示SPAGE比Wald检验快33-79倍,比Firth’s test 快72-439倍。因此,对于一次全基因组GxE分析,运算时间可以从几个月降低到几天甚至几小时。另一方面,在Biobank中,大部分疾病的病例对照(case-control)比例很低,比如UK-Biobank中约有84.8% (1,431/1,688)的疾病的病例对照比例低于1:100。如果使用传统的正态分布近似(normal approximation),这种病例对照不平衡会导致大量的假阳性结果。本文使用鞍点逼近法来计算p值,这种近似方法相对于正态分布近似更准确,所以可以更好的控制第一类错误率,避免假阳性结果。数值模拟结果显示,即使在高度的病例对照不平衡(1:100)下针对罕见变异(MAF=0.001)的分析,SPAGE仍然可以非常好地控制第一类错误率,同时具有相当高的统计效能。
本文将该方法应用于UK-Biobank数据中,分析了79对环境因素与表型的组合,其中环境因素包含抽烟,酒精摄入,性别和身体锻炼情况,表型包含慢性阻塞性呼吸障碍、高血脂、心率失常等多种复杂疾病。分析中包含344,341个欧洲人样本和大约2,800万个填充(imputation)后的SNP位点。在显著性水平5e-8下,分析发现了34个具有显著交互作用的SNP位点。比如,位于基因CHRNA5上的位点rs55781567对于慢性阻塞性呼吸障碍的影响与抽烟行为相关。该位点上等位基因G的携带者更容易患有呼吸障碍,而对于抽烟者,这种易感性会显著增大。本文还讨论了基因PITX2与性别的交互作用对于心率失常,以及基因DNAH11与身体锻炼的交互作用对于高血脂的影响。
总之,本文提出了一个快速且准确的新算法SPAGE。数值模拟和实际数据分析表明该方法可以极大地提升运算速度,同时可以很好地控制第一类错误率。通过应用于UK-Biobank数据,该方法成功发现了多个具有显著交互作用的SNP位点。SPAGE的R包可以从网站https://github.com/WenjianBI/SPAGE下载。UK-Biobank的数据分析结果可从网站https://www.leelabsg.org/resources下载。
参考文献:
https://doi.org/10.1016/j.ajhg.2019.10.008
-
政策法规

-
焦点事件

-
标准
-
企业风采

-
科技前沿

-
政策法规

-
焦点事件

-
焦点事件

-
政策法规
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件

-
政策法规

-
焦点事件

-
焦点事件

-
产品技术
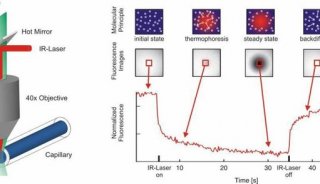
-
焦点事件
-
焦点事件
-
焦点事件

-
标准

-
焦点事件

-
焦点事件

-
焦点事件
-
项目成果

-
科技前沿

-
科技前沿

-
综述
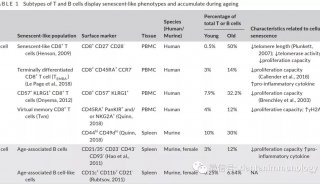
-
焦点事件

-
焦点事件

-
焦点事件

-
政策法规
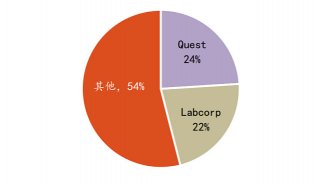
-
综述
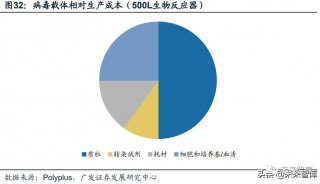
-
焦点事件

-
技术原理
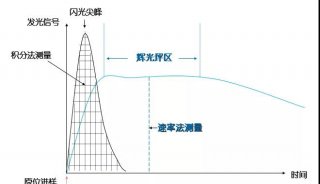
-
技术原理
-
精英视角

-
科技前沿

-
焦点事件
-
科技前沿

-
科技前沿
-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件

-
综述

-
焦点事件
-
焦点事件

-
焦点事件
-
科技前沿
-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件
-
焦点事件

-
焦点事件
-
实验室动态

-
焦点事件
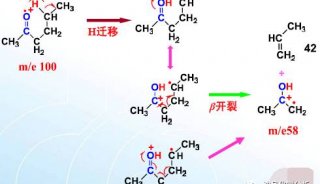
-
技术原理

-
焦点事件
-
项目成果

-
焦点事件
-
焦点事件

-
焦点事件
-
会议会展

-
综述
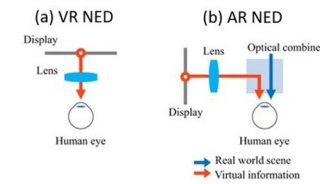
-
实验室动态

-
科技前沿

-
政策法规

-
政策法规

-
焦点事件
-
焦点事件
-
焦点事件

-
技术原理
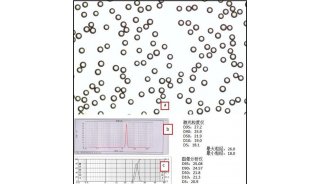
-
焦点事件